学习:从训练数据中获得最优权重参数。
4.1从数据中学习
即由数据自动决定权重参数的值

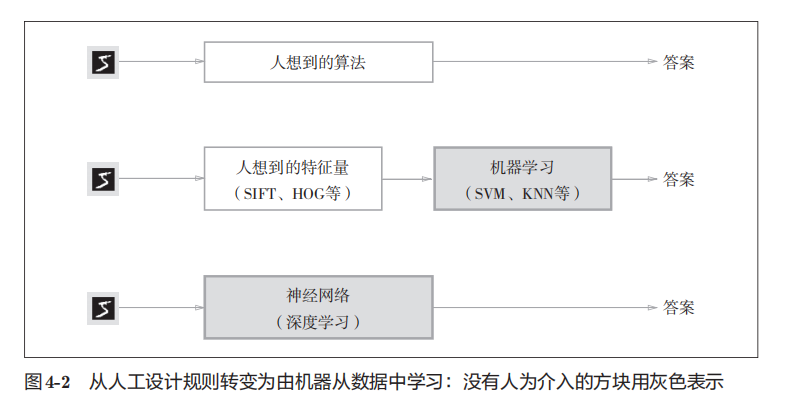
以手写数字识别为例,人工来设计程序是一个很难的问题。那我们就可以有效利用数据。
方案 1机器学习
先从图像中提取特征量,再用机器学习技术学习这些特征量
即 使用这些特征量将图像数据转换为向量,然后对转换后的向量使用机器学习中的SVM、KNN等分类器进行学习
“特征量”:是指可以从输入数据(输入图像)中准确地提取本质数据(重要的数据)的转换器。图像的特征量通常表示为向量的形式
但是,将图像转换为向量时使用的特征量仍是由人设计的。对于不同的问题,必须使用合适的特征量
方案2神经网络
神经网络直接学习图像本身,图像中包含的重要特征量也都是由机器来学习的
训练数据和测试数据
机器学习中,一般将数据分为训练数据和测试数据两部分来进行学习和实验等
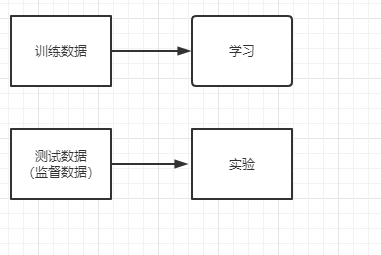
我们追求的是模型的泛化能力,即处理不包含在训练数据中的能力,不能用一个数据集既来训练又来测试,避免只对某个数据集过度拟合
知道了学习,怎么衡量学习的效果呢?
4.2损失函数
神经网络的学习通过某个指标表示现在的状态。然后,以这个指标为基准,寻找最优权重参数。神经网络的学习中所用的指标称为损失函数。通常使用均方误差和交叉熵误差
4.2.1均方误差
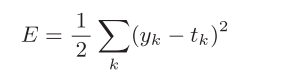
![]()
一个例子:

t是监督数据,将正确解的标签设置为1,其他标签表示为0的表示方法称为one-hot表示
神经网络的输出y是softmax函数的输出
均方误差会计算神经网络的输出和正确解监督数据的各个元素之差的平方,再求总和。
4.2.2交叉熵误差
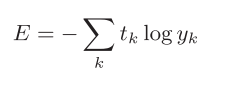

交叉熵误差的值是由正确解标签所对应的输出结果决定的
4.2.3 mini-batch学习
机器学习使用训练数据进行学习,就是针对训练数据计算损失函数的值,找出使该值尽可能小的参数
考虑所有训练数据的损失函数的总和,以交叉熵误差为例
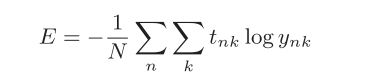
如果遇到大数据,数据量成千上万,全部计算损失函数就不太现实。
因此,我们从全部数据中选出一部分,作为全部数据的“近似”。神经网络的学习也是从训练数据中选出一批数据(称为mini-batch,小批量),然后对每个mini-batch进行学习。称为mini-batch学习
4.2.5 为何要设定损失函数
为什么不直接用识别精度作为指标?
根据“导数”在神经网络学习中的作用来回答
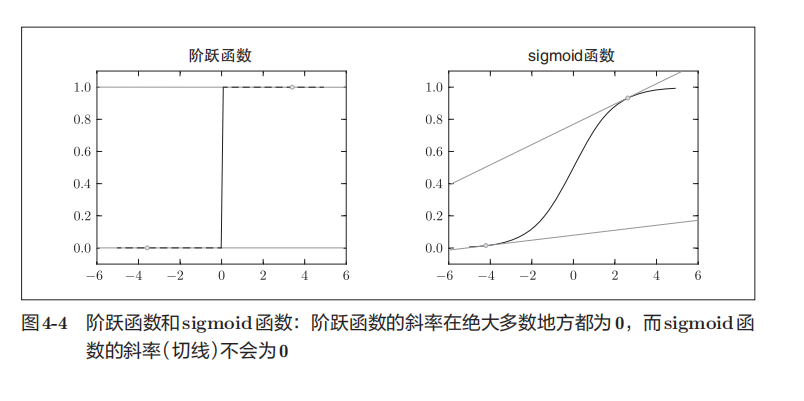
对神经网络的某一个权重参数的损失函数求导,表示的是“如果稍微改变这个权重参数的值,损失函数的值会如何变化”。根据导数值的正负来判断损失函数的单调性,进而通过改变权重参数来减小损失函数。但是,当导数为0时,无论权重参数如何变化,损失函数的值都不变。
而使用识别精度作为指标,识别精度对微小的参数变化基本上没有什么反应,即便有反应,它的值
也是不连续地、突然地变化,比如从32%变到33%等不连续的、离散的值而不是32.102%。故不能将识别精度作为指标,参数的稻数在绝大多数地方都会变为0.
出于相同的原因,如果使用阶跃函数作为激活函数,神经网络的学习将无法进行.。如果使用了阶跃函数,那么即便将损失函数作为指标,参数的微小变化也会被阶跃函数抹杀,导致损失函数的值不会产生任何变化。而sigmoid函数的导数在任何地方都不为0
4.3数值微分
4.3.1导数
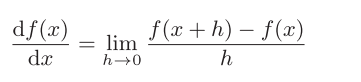

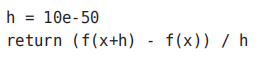
函数numerical_diff(f, x)的名称来源于数值微分
h有舍入误差
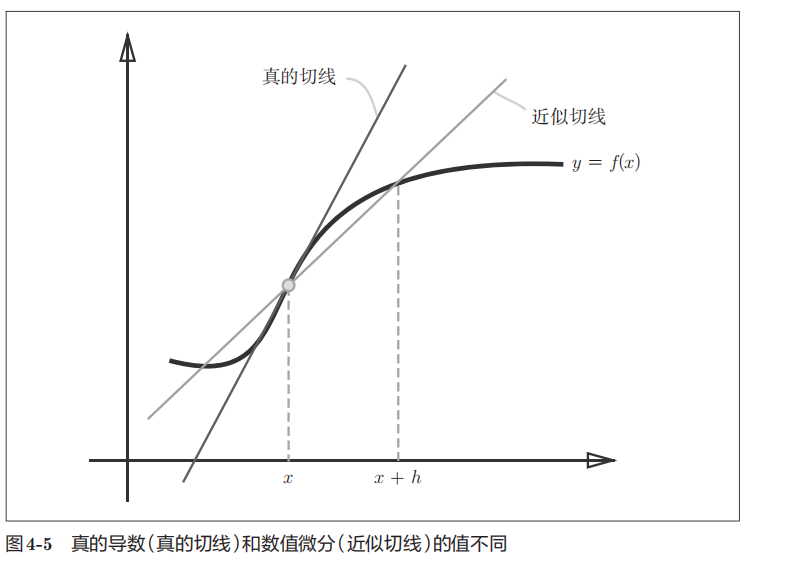
“真的导数”对应函数在x处的斜率(称为切线),但上述实现中计算的导数对应的是(x + h)和x之间的斜率。为了减小这个误差,我们可以计算函数f在(x + h)和(x − h)之间的差分。因为这种计算方法以x为中心,计算它左右两边的差分,所以也称为中心差分(而(x + h)和x之间的差分称为前向差分)
4.3.2偏导数
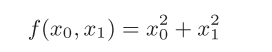

4.4梯度
一起计算x0和x1的偏导,![]() 而成的向量称为梯度(gradient)
而成的向量称为梯度(gradient)
梯度指向函数f(x0,x1)的“最低处”(最小值)
4.4.1梯度法
神经网络必须在学习时找到最优参数(权重和偏置)。这里所说的最优参数是指损失函数取最小值时的参数。可以通过梯度法寻找函数最小值。
极小值是局部最小值,也就是限定在某个范围内的最小值。虽然梯度的方向并不一定指向最小值,但沿着它的方向能够最大限度地减小函数的值。
在梯度法中,函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度方向前进, 如此反复,不断地沿梯度方向前进
用数学式表示梯度法
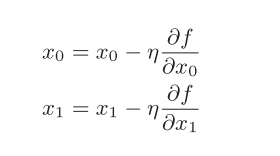
η表示更新量,在神经网络的学习中,称为学习率。学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数。这个式子会反复执行,更新变量的值,逐渐减小函数值。
像学习率这样的参数称为超参数,通常是人工设定的
4.4.2神经网络的梯度
神经网络的学习也要求梯度。这里所说的梯度是指损失函数关于权重参数的梯度


