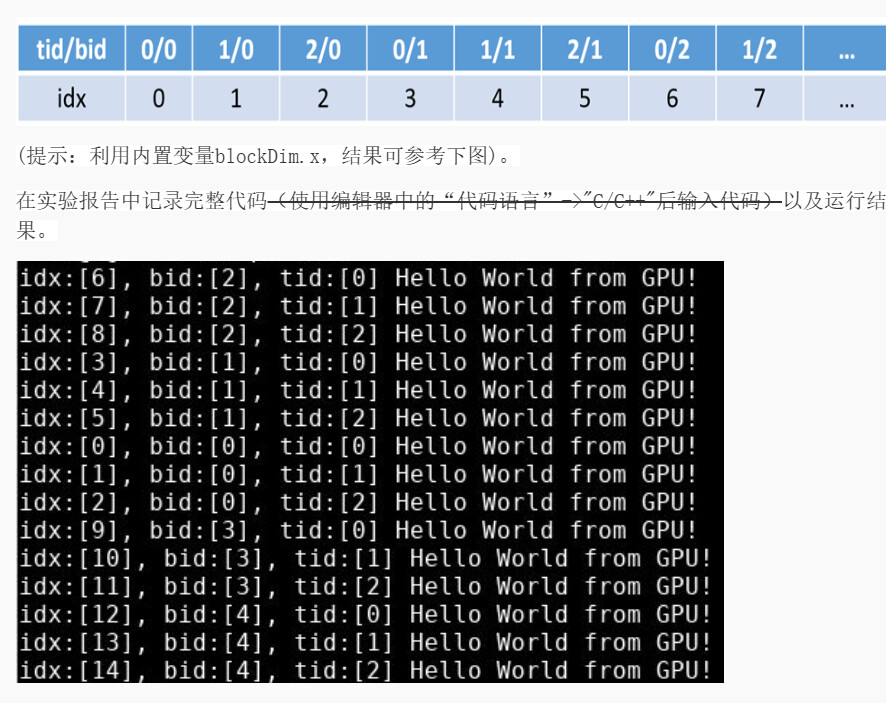
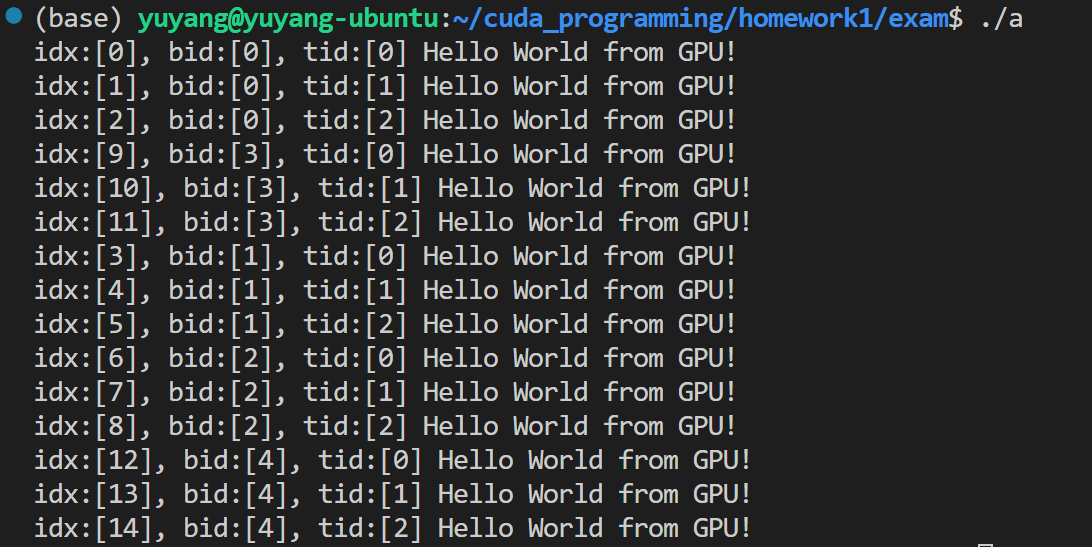
近期选了一门GPU编程,正好对GPU编程方向在学习,以及被迫营业的项目需求(。这里对我自己学习GPU编程的内容进行一些资料博客的整理。
学习CUDA编程神项目: PacktPublishing/Learn-CUDA-Programming: Learn CUDA Programming, published by Packt (github.com)
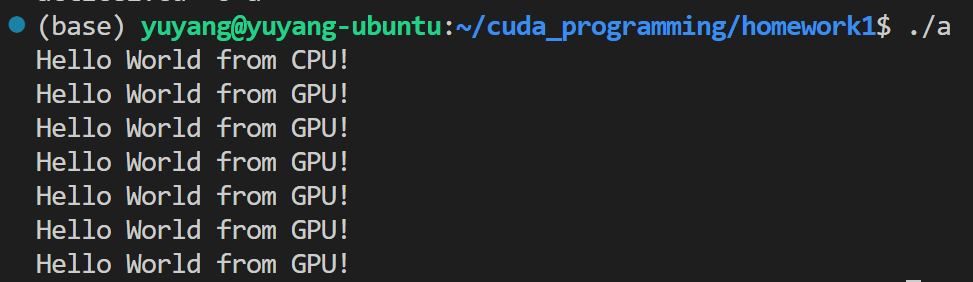
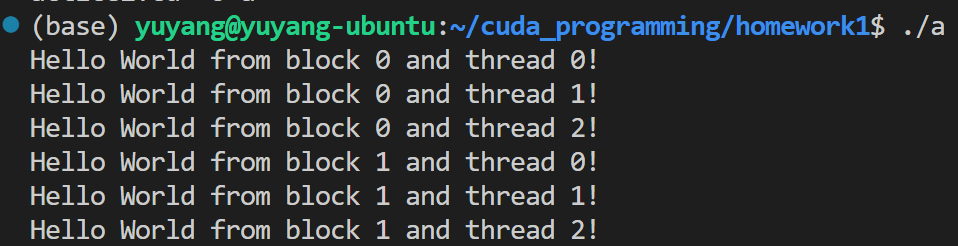
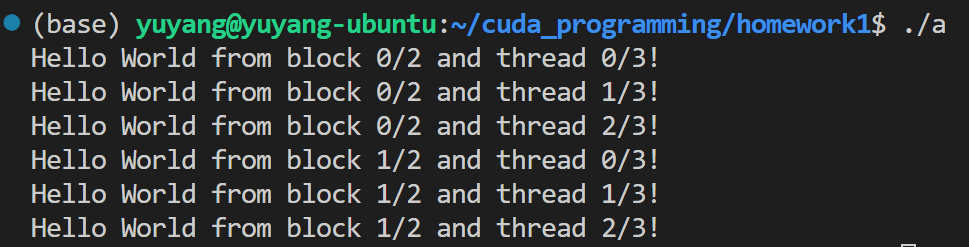
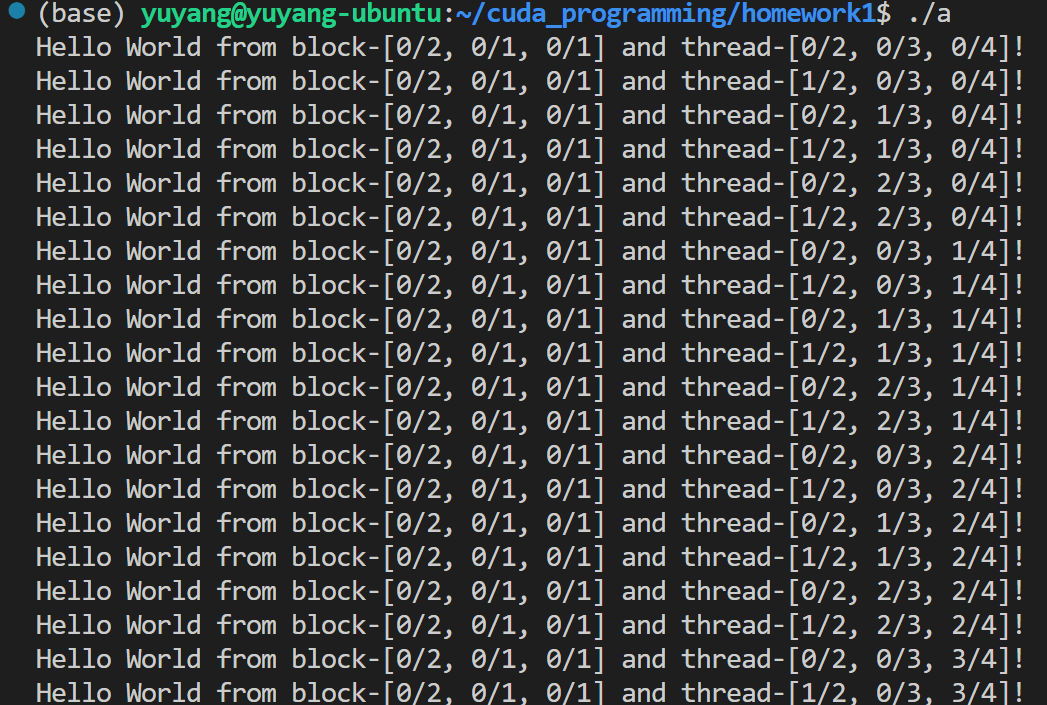
手把手带着从CUDA版的“Hello World“开始搓!
原书可以从zlibrary 嫖Z-Library – the world’s largest e-book library. Your gateway to knowledge and culture.(大陆没有这个源文件)
【资料整理】
Ⅰ. CUDA/cudnn/CUDA Toolkit/NVCC
参考:
CUDA Runtime API :: CUDA Toolkit Documentation (nvidia.com)
Pytorch 使用不同版本的 cuda - yhjoker - 博客园 (cnblogs.com)
显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么? - 知乎 (zhihu.com)
安装多版本 cuda ,多版本之间切换_cuda 切换版本-CSDN博客
Linux中PATH、 LIBRARY_PATH、 LD_LIBRARY_PATH的区别_慕课手记 (imooc.com)
Nvidia-smi简介及常用指令及其参数说明_nvidia-smi的作用-CSDN博客
一张图了解GPU、CUDA、CUDA toolkit和pytorch的关系_cuda和pytorch的关系-CSDN博客
简介:
CUDA 为“GPU通用计算”构建的运算平台。
CUDA是显卡厂商NVIDIA推出的运算平台。CUDA™是一种由NVIDIA推出的通用并行计算架构,是一种并行计算平台和编程模型,该架构使GPU能够解决复杂的计算问题。CUDA英文全称是Compute Unified Device Architecture。
有人说:CUDA是一门编程语言,像C,C++,python 一样,也有人说CUDA是API。
官方说:CUDA是一个并行计算平台和编程模型,能够使得使用GPU进行通用计算变得简单和优雅。
运行CUDA应用程序要求系统至少具有一个具有CUDA功能的GPU和与CUDA Toolkit兼容的驱动程序。
cudnn为深度学习计算设计的软件库。
CUDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算;
来自知乎的解释:CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装cuDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。
基本上所有的深度学习框架都支持cuDNN这一加速工具,例如:Caffe、Caffe2、TensorFlow、Torch、Pytorch、Theano等。
CUDA Toolkit (nvidia): CUDA完整的工具安装包,其中提供了 Nvidia 驱动程序、开发 CUDA 程序相关的开发工具包等可供安装的选项。包括 CUDA 程序的编译器、IDE、调试器等,CUDA 程序所对应的各式库文件以及它们的头文件。
CUDA工具包的主要包含了CUDA-C和CUDA-C++编译器、一些科学库和实用程序库、CUDA和library API的代码示例、和一些CUDA开发工具。(通常在安装CUDA Toolkit的时候会默认安装CUDA Driver;但是我们经常只安装CUDA Driver,没有安装CUDA Toolkit,因为有时不一定用到CUDA Toolkit;比如我们的笔记本电脑,安装个CUDA Driver就可正常看视频、办公和玩游戏了)
CUDA Toolkit (Pytorch): CUDA不完整的工具安装包,其主要包含在使用 CUDA 相关的功能时所依赖的动态链接库。不会安装驱动程序。
NVCC :CUDA的编译器,只是 CUDA Toolkit 中的一部分
NVCC就是CUDA的编译器,可以从CUDA Toolkit的/bin目录中获取,类似于gcc就是c语言的编译器。由于程序是要经过编译器编程成可执行的二进制文件,而cuda程序有两种代码,一种是运行在cpu上的host代码,一种是运行在gpu上的device代码,所以nvcc编译器要保证两部分代码能够编译成二进制文件在不同的机器上执行。
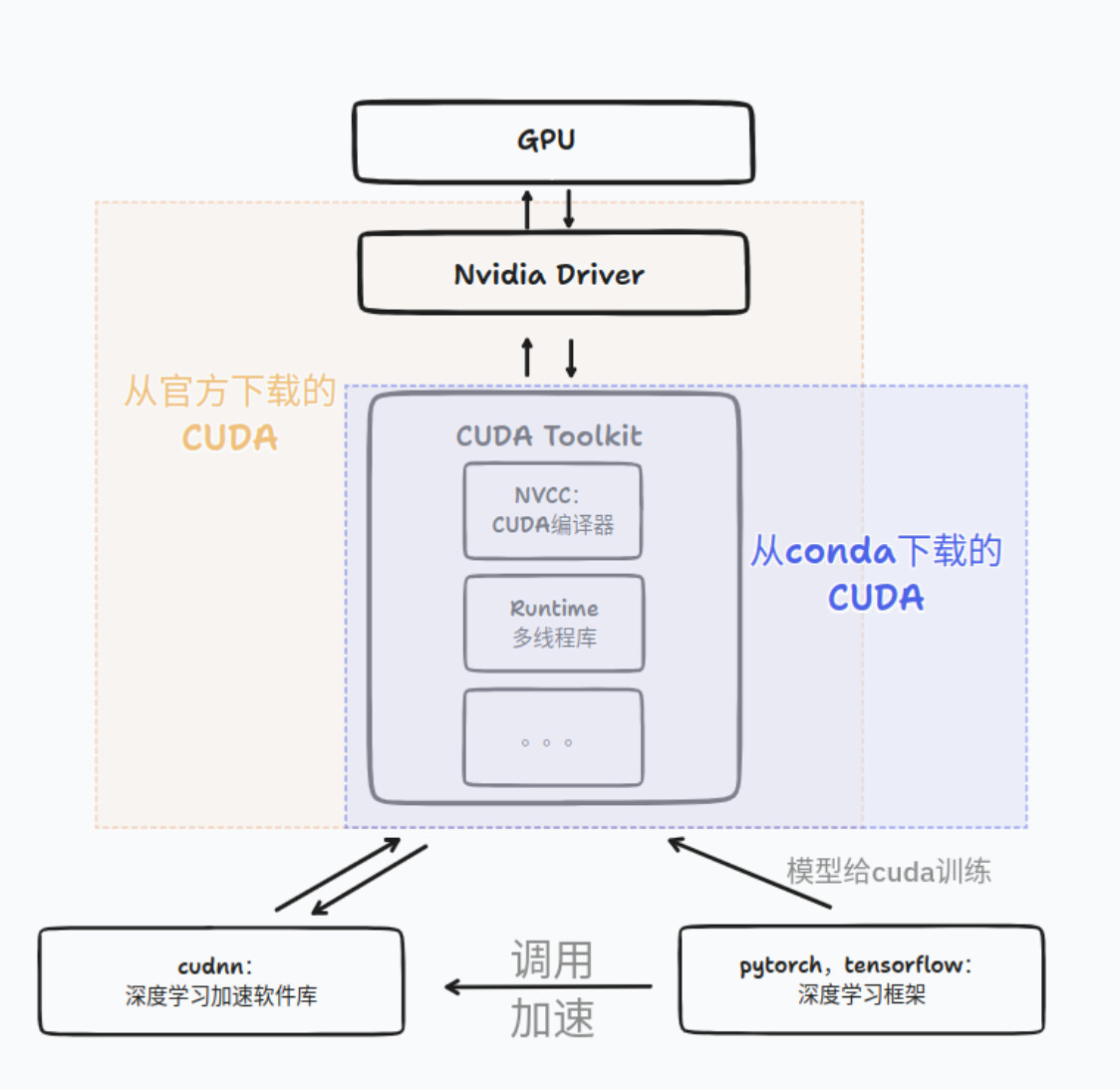
1. cuda 与 cudatoolkit 的区别
在使用 Anaconda 安装 Pytorch 深度学习框架时,可以发现 Anaconda 会自动为我们安装 cudatoolkit.
上述安装的 cudatoolkit 与通过 Nvidia 官方提供的 CUDA Toolkit 是不一样的。具体而言,Nvidia 官方提供的 CUDA Toolkit 是一个完整的工具安装包,其中提供了 Nvidia 驱动程序、开发 CUDA 程序相关的开发工具包等可供安装的选项。使用 Nvidia 官网提供的 CUDA Toolkit 可以安装开发 CUDA 程序所需的工具,包括 CUDA 程序的编译器、IDE、调试器等,CUDA 程序所对应的各式库文件以及它们的头文件。上述 CUDA Toolkit 的具体组成可参考 CUDA Toolkit Major Components.
实际上,Nvidia 官方提供安装的 CUDA Toolkit 包含了进行 CUDA 相关程序开发的编译、调试等过程相关的所有组件。但对于 Pytorch 之类的深度学习框架而言,其在大多数需要使用 GPU 的情况中只需要使用 CUDA 的动态链接库支持程序的运行( Pytorch 本身与 CUDA 相关的部分是提前编译好的 ),就像常见的可执行程序一样,不需要重新进行编译过程,只需要其所依赖的动态链接库存在即可正常运行。故而,Anaconda 在安装 Pytorch 等会使用到 CUDA 的框架时,会自动为用户安装 cudatoolkit,其主要包含应用程序在使用 CUDA 相关的功能时所依赖的动态链接库。在安装了 cudatoolkit 后,只要系统上存在与当前的 cudatoolkit 所兼容的 Nvidia 驱动,则已经编译好的 CUDA 相关的程序就可以直接运行,而不需要安装完整的 Nvidia 官方提供的 CUDA Toolkit .
通过 Anaconda 安装的应用程序包位于安装目录下的 /pkg 文件夹中,如笔者的目录即为 /home/xxx/anaconda3/pkgs/ ,用户可以在其中查看 conda 安装的 cudatoolkit 的内容,如下图所示。可以看到 conda 安装的 cudatoolkit 中主要包含的是支持已经编译好的 CUDA 程序运行的相关的动态链接库。( Ubuntu 环境下 )
在大多数情况下,上述 cudatoolkit 是可以满足 Pytorch 等框架的使用需求的。但对于一些特殊需求,如需要为 Pytorch 框架添加 CUDA 相关的拓展时( Custom C++ and CUDA Extensions ),需要对编写的 CUDA 相关的程序进行编译等操作,则需安装完整的 Nvidia 官方提供的 CUDA Toolkit.
Pytorch 确定所使用的 cuda 版本
实际使用过程中,Pytorch 检测运行时使用的 cuda 版本的代码位于 torch/utils/cpp_extension.py 的_find_cuda_home 函数 ( Pytorch 1.1.0, Line 24 )中.这里主要介绍 Linux 环境下的 cuda 版本的确认过程,关于 Windows 环境下多版本 cuda 的使用可以参考上述文件中的具体实现.
确定 cuda 路径
若在运行时需要使用 cuda 进行程序的编译或其他 cuda 相关的操作,Pytorch 会首先定位一个 cuda 安装目录( 来获取所需的特定版本 cuda 提供的可执行程序、库文件和头文件等文件 )。具体而言,Pytorch 首先尝试获取环境变量 CUDA_HOME/CUDA_PATH 的值作为运行时使用的 cuda 目录。若直接设置了 CUDA_HOME/CUDA_PATH 变量,则 Pytorch 使用 CUDA_HOME/CUDA_PATH 指定的路径作为运行时使用的 cuda 版本的目录。
若上述环境变量不存在,则 Pytorch 会检查系统是否存在固定路径 /usr/local/cuda 。默认情况下,系统并不存在对环境变量 CUDA_HOME 设置,故而 Pytorch 运行时默认检查的是 Linux 环境中固定路径 /usr/local/cuda 所指向的 cuda 目录。 /usr/local/cuda 实际上是一个软连接文件,当其存在时一般被设置为指向系统中某一个版本的 cuda 文件夹。使用一个固定路径的软链接的好处在于,当系统中存在多个安装的 cuda 版本时,只需要修改上述软连接实际指向的 cuda 目录,而不需要修改任何其他的路径接口,即可方便的通过唯一的路径使用不同版本的 cuda. 如笔者使用的服务器中,上述固定的 /usr/local/cuda 路径即指向一个较老的 cuda-8.0 版本的目录。
需要注意的是, /usr/local/cuda 并不是一个 Linux 系统上默认存在的路径,其一般在安装 cuda 时创建( 为可选项,不强制创建 )。故而 Pytorch 检测上述路径时也可能会失败。
若 CUDA_HOME 变量指定的路径和默认路径 /usr/local/cuda 均不存在安装好的 cuda 目录,则 Pytorch 通过运行命令 which nvcc 来找到一个包含有 nvcc 命令的 cuda 安装目录,并将其作为运行时使用的 cuda 版本。具体而言,系统会根据环境变量 PATH 中的目录去依次搜索可用的 nvcc 可执行文件,若环境变量 PATH 中包含多个安装好的 cuda 版本的可执行文件目录( 形如/home/test/cuda-10.1/bin ),则排在 PATH 中的第一个 cuda 的可执行文件目录中的 nvcc 命令会被选中,其所对应的路径被选为 Pytorch 使用的 cuda 路径。同样的,若 PATH 中不存在安装好的 cuda 版本的可执行目录,则上述过程会失败,Pytorch 最终会由于找不到可用的 cuda 目录而无法使用 cuda.比较推荐的做法是保持 PATH 路径中存在唯一一个对应所需使用的 cuda 版本的可执行目录的路径。
在确定好使用的 cuda 路径后,基于 cuda 的 Pytorch 拓展即会使用确定好的 cuda 目录中的可执行文件( /bin )、头文件( /include )和库文件( /lib64 )完成所需的编译过程。
Pytorch 使用特定的 cuda 版本
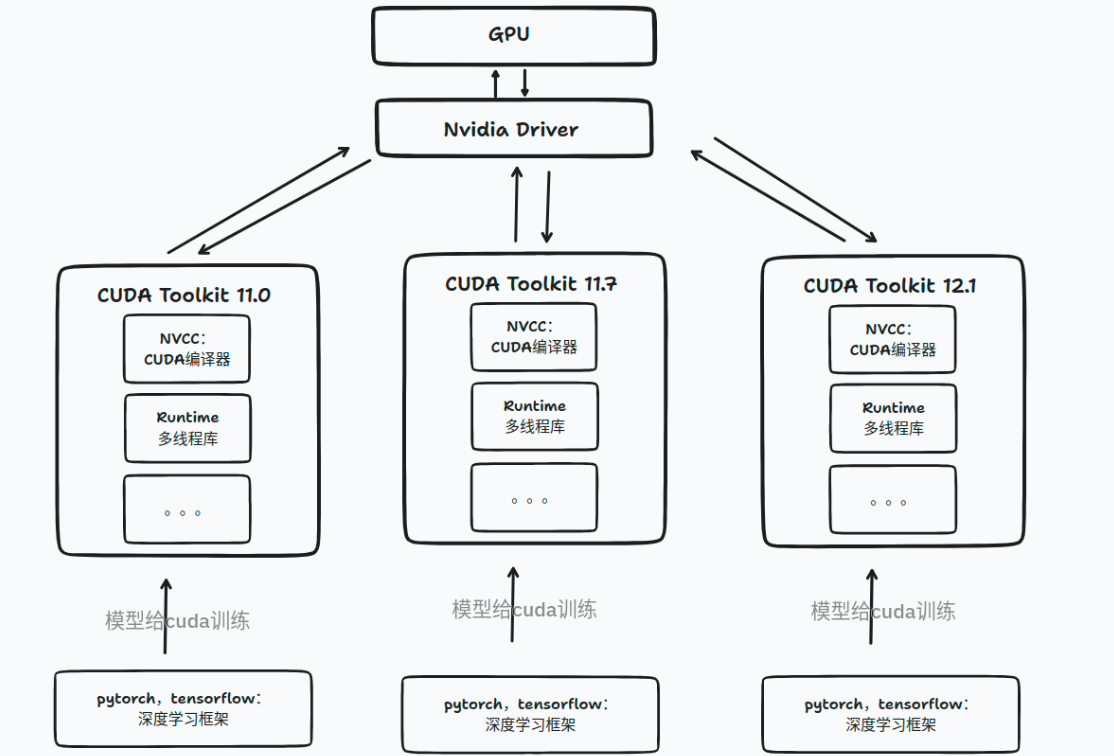
从 Pytorch 确定使用的 cuda 版本的流程来看,想要指定 Pytorch 使用的 cuda 版本,主要有两种方法,第一种是修改软链接 /usr/local/cuda 所指向的 cuda 安装目录( 若不存在则新建 ),第二种是通过设置环境变量 CUDA_HOME 指向所需使用的 cuda 版本的安装目录。除此之外,还建议将对应 cuda 目录中的可执行文件目录( 形如/home/test/cuda-10.1/bin )加入环境变量 PATH 中。
对于第一种方法,由于 /usr/ 和 /usr/local/ 目录下的文件均为 root 用户所管理,故而普通用户无法对其进行修改。对于具备了 root 权限的用户而言,在安装有多版本 cuda 的 Linux 系统上,只需切换 /usr/local/cuda 所指向的 cuda 目录,让其指向所需的 cuda 版本的安装位置,即可让 Pytorch 在运行时使用指定版本的 cuda 运行程序。修改软链接的方法如下命令所示,命令删除原有的软链接,并新建指向新路径的软链接。
sudo rm -rf /usr/local/cuda //删除软链接,注意是 /usr/local/cuda 而不是 /usr/local/cuda/,前者仅删除软链接,而后者会删除软链接所指向的目录的所有内容,操作请小心
sudo ln -s cuda_path /usr/local/cuda //创建名为 /usr/local/cuda 的软链接,其指向 cuda_path 所指定的 cuda 安装目录
或者直接强制修改原始的软链接
sudo ln -sf cuda_path /usr/local/cuda //修改或创建软链接 /usr/local/cuda 使其指向指定版本的 cuda 目录
对于非 root 用户而言,主要通过第二种方法进行设置。若想要指定 Pytorch 使用的 cuda 版本,则首先需要设置 CUDA_HOME 环境变量,之后在 PATH 中加入指定 cuda 版本的可执行目录,也就时 cuda_path/bin/ 目录。完成设置后,运行 Pytorch 时所使用的即为对应的 cuda 版本。
实例
以笔者的服务器账户为例,笔者在 /home/test/cuda-10.1 目录中安装了 cuda-10.1 ,而服务器上的 /usr/local/cuda 目录指向的是之前安装的老版本的 cuda-8.0,直接运行 Pytorch 时,其会基于上面的确认流程直接使用老版本的 cuda .若想要临时设置 Pytorch 使用新安装的 cuda ,则可以通过 export 命令修改全局变量。这种设置方式在当前终端退出后即失效。
export CUDA_HOME=/home/test/cuda-10.1/ //设置全局变量 CUDA_HOME
export PATH=$PATH:/home/test/cuda-10.1/bin/ //在 PATH 变量中加入需要使用的 cuda 版本的路径,使得系统可以使用 cuda 提供的可执行文件,包括 nvcc
想要永久设置上述 cuda 设置,用户可以直接在自己的 bash 设置文件 ~/.bashrc 文件尾部加入上述命令,保存后再通过 source ~/.bashrc 执行文件,即可完成当前终端的环境变量修改。如果需要使用新的 cuda 来编译文件,还可以通过 LD_LIBRARY_PATH 变量指定进行链接的 cuda 库文件的路径。
位于 ~/.bashrc 文件中的指令在每次终端启动时均会自动运行,后续本用户所打开的终端中的环境变量均会首先执行上述文件中的命令,从而获得对应的 cuda 变量。
获取 Pytorch 使用的 cuda 版本
目前,网络上比较多的资源会讨论如何获得 Pytorch 使用的 cuda 的版本的方法。比较主流的一种方法是使用 Pytorch 提供的方法 torch.version.cuda .
>>>import torch
>>>torch.version.cuda #输出一个 cuda 版本
事实上,上述输出的 cuda 的版本并不一定是 Pytorch 在实际系统上运行时使用的 cuda 版本,而是编译该 Pytorch release 版本时使用的 cuda 版本。
torch.version.cuda 是位于 torch/version.py 中的一个变量, Pytorch 在基于源码进行编译时,通过 tools/setup_helpers/cuda.py 来确定编译 Pytorch 所使用的 cuda 的安装目录和版本号,确定的具体流程与 Pytorch 运行时确定运行时所使用的 cuda 版本的流程较为相似,具体可以见其源码( Pytorch 1.1.0, Line 66 ).在进行 Pytorch 源码编译时,根目录下的 setup.py 会调用上述代码,确定编译 Pytorch 所使用的 cuda 目录和版本号,并使用获得的信息修改 torch/version.py 中的 cuda 信息( Pytorch, Line 286 )。上述 torch.version.cuda 输出的信息即为编译该发行版 Pytorch 时所使用的 cuda 信息。若系统上的 Pytorch 通过 conda 安装,用户也可以直接通过 conda list | grep pytorch 命令查看安装的 Pytorch 的部分信息。
conda list | grep pytorch //查看安装的 Pytorch 的信息
笔者环境下上述命令的结果如图所示,可以看到显示的 cuda 信息与 torch.version.cuda 保持一致。
想要查看 Pytorch 实际使用的运行时的 cuda 目录,可以直接输出之前介绍的 cpp_extension.py 中的 CUDA_HOME 变量。
>>> import torch
>>> import torch.utils
>>> import torch.utils.cpp_extension
>>> torch.utils.cpp_extension.CUDA_HOME #输出 Pytorch 运行时使用的 cuda
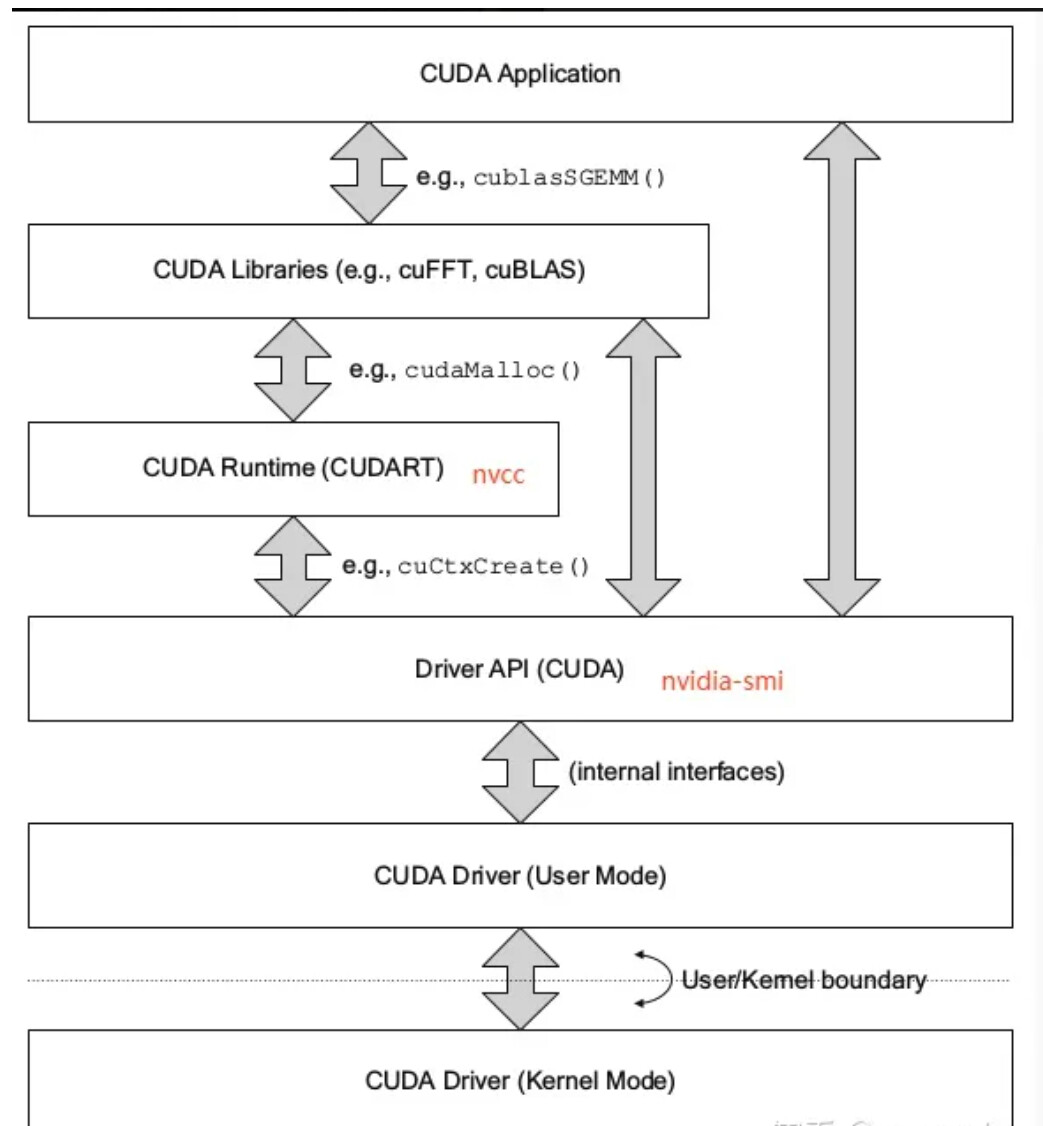
2.nvcc和nvidia-smi显示的CUDA版本不同?
在实验室的服务器上nvcc --version显示的结果如下:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Tue_Jun_12_23:07:04_CDT_2018
Cuda compilation tools, release 9.2, V9.2.148
而nvidia-smi显示结果如下:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.104 Driver Version: 410.104 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-PCIE... On | 00000000:01:00.0 Off | Off |
| N/A 28C P0 26W / 250W | 0MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P100-PCIE... On | 00000000:02:00.0 Off | Off |
| N/A 24C P0 30W / 250W | 0MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
可以看到nvcc的CUDA 版本是9.2,而nvidia-smi的CUDA版本是10.0。很奇怪的是有时候绝大多数情况代码也能整成跑起来,stackoverflow上的一个解释如下:
CUDA有两个主要的API:runtime(运行时) API和driver API。这两个API都有对应的CUDA版本(如9.2和10.0等)。
- 用于支持driver API的必要文件(如
libcuda.so)是由GPU driver installer安装的。nvidia-smi就属于这一类API。 - 用于支持runtime API的必要文件(如
libcudart.so以及nvcc)是由CUDA Toolkit installer安装的。(CUDA Toolkit Installer有时可能会集成了GPU driver Installer)。nvcc是与CUDA Toolkit一起安装的CUDA compiler-driver tool,它只知道它自身构建时的CUDA runtime版本。它不知道安装了什么版本的GPU driver,甚至不知道是否安装了GPU driver。
综上,如果driver API和runtime API的CUDA版本不一致可能是因为你使用的是单独的GPU driver installer(显卡驱动里的GPU driver installer),而不是CUDA Toolkit installer里的GPU driver installer。runtime和driver API在很多情况非常相似,也就是说用起来的效果是等价的,但是你不能混合使用这两个API,因为二者是互斥的。也就是说在开发过程中,你只能选择其中一种API。简单理解二者的区别就是:runtime是更高级的封装,开发人员用起来更方便,而driver API更接近底层,速度可能会更快。两者的区别:
-
复杂性
-
- runtime API通过提供隐式初始化、上下文管理和模块管理来简化设备代码管理。这使得代码更简单,但也缺乏驱动程序API所具有的控制级别。
- 相比之下,driver API提供了更细粒度的控制,特别是在上下文和模块加载方面。实现内核启动要复杂得多,因为执行配置和内核参数必须用显式函数调用指定。
-
控制
-
- 对于runtime API,其在运行时,所有内核都在初始化期间自动加载,并在程序运行期间保持加载状态。
- 而使用driver API,可以只加载当前需要的模块,甚至动态地重新加载模块。driver API也是语言独立的,因为它只处理
cubin对象。
-
上下文管理
- 上下文管理可以通过driver API完成,但是在runtime API中不公开。相反,runtime API自己决定为线程使用哪个上下文。
-
- 如果一个上下文通过driver API成为调用线程的当前上下文,runtime将使用它。
- 如果没有这样的上下文,它将使用“主上下文(primary context)”。

3. PATH
PATH是可执行文件路径,是三个中我们最常接触到的,因为我们命令行中的每句能运行的命令,如ls、top、ps等,都是系统通过PATH找到了这个命令执行文件的所在位置,再run这个命令(可执行文件)。 比如说,在用户的目录~/mycode/下有一个bin文件夹,里面放了有可执行的二进制文件、shell脚本等。如果想要在任意目录下都能运行上述bin文件夹的可执行文件,那么只需要把这个bin的路径添加到PATH即可,方法如下:
# vim ~/.bashrc
PATH=$PATH:~/mycode/bin
4. LIBRARY_PATH和LD_LIBRARY_PATH
这两个路径可以放在一起讨论,
-
LIBRARY_PATH是程序编译期间查找动态链接库时指定查找共享库的路径 -
LD_LIBRARY_PATH是程序加载运行期间查找动态链接库时指定除了系统默认路径之外的其他路径
两者的共同点是库,库是这两个路径和PATH路径的区别,PATH是可执行文件。
两者的差异点是使用时间不一样。一个是编译期,对应的是开发阶段,如gcc编译;一个是加载运行期,对应的是程序已交付的使用阶段。
配置方法也是类似:
export LD_LIBRARY_PATH=LD_LIBRARY_PATH:XXXX
Ⅱ. CUDA Toolkit具体组成
参考:CUDA 12.3 Update 2 Release Notes (nvidia.com)
-
CUDA Samples: 演示如何使用各种CUDA和library API的代码示例。可在Linux和Mac上的
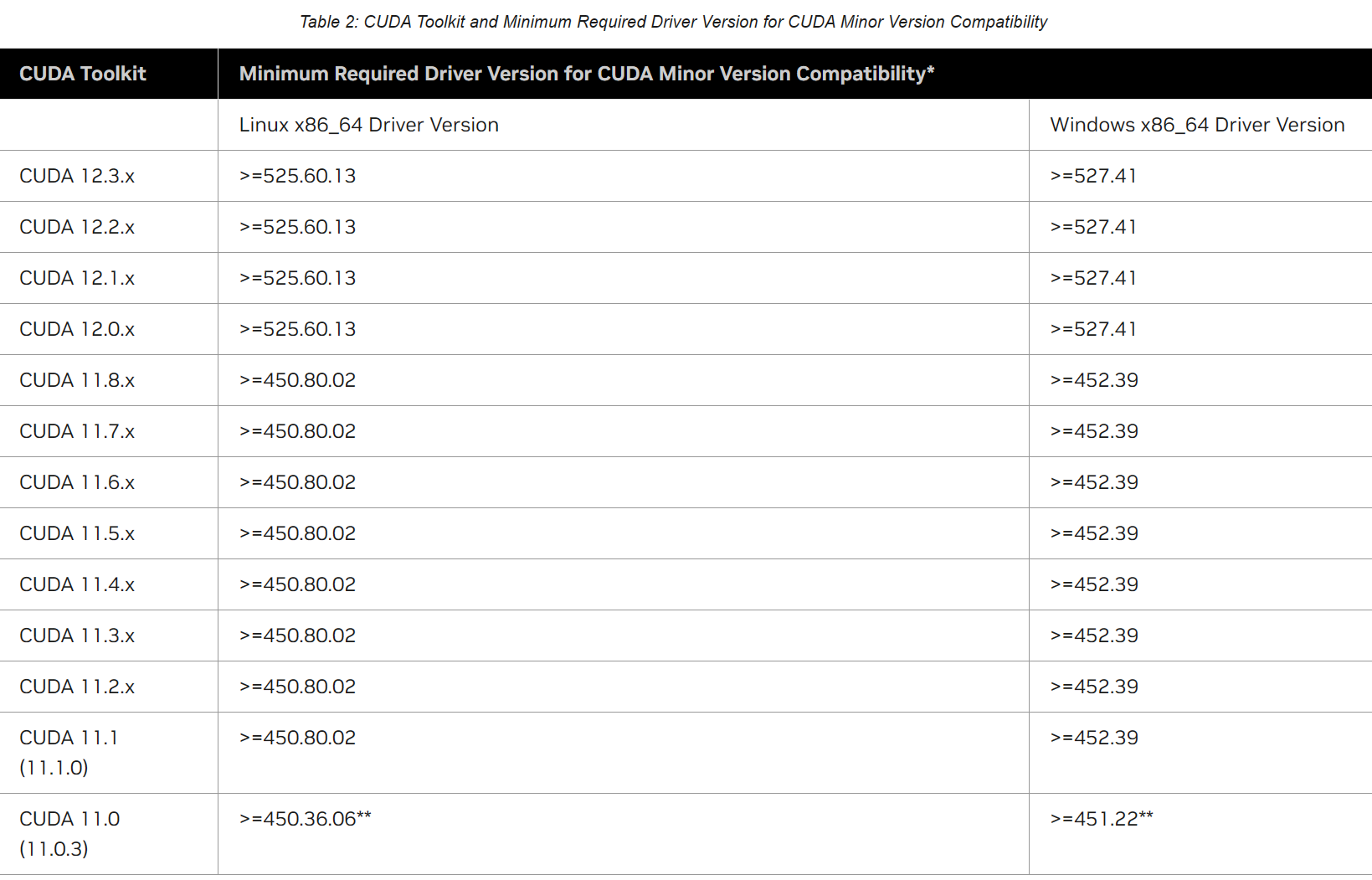
samples/目录中获得,Windows上的路径是C:\ProgramData\NVIDIA Corporation\CUDA Samples中。在Linux和Mac上,samples/目录是只读的,如果要对它们进行修改,则必须将这些示例复制到另一个位置。 - CUDA Driver: 运行CUDA应用程序需要系统至少有一个具有CUDA功能的GPU和与CUDA工具包兼容的驱动程序。每个版本的CUDA工具包都对应一个最低版本的CUDA Driver,也就是说如果你安装的CUDA Driver版本比官方推荐的还低,那么很可能会无法正常运行。CUDA Driver是向后兼容的,这意味着根据CUDA的特定版本编译的应用程序将继续在后续发布的Driver上也能继续工作。通常为了方便,在安装CUDA Toolkit的时候会默认安装CUDA Driver。在开发阶段可以选择默认安装Driver,但是对于像Tesla GPU这样的商用情况时,建议在官方安装最新版本的Driver。 目前(2024年2月)的CUDA Toolkit和CUDA Driver版本的对应情况如下:
Ⅲ. NVCC简介
- nvcc其实就是CUDA的编译器,cuda程序有两种代码, 在cpu上的host代码和在gpu上的device代码。
- .cu后缀:cuda源文件,包括host和device代码
- nvcc编译例子
nvcc –cuda x.cu –keep
# x.cudafe1.gpu
# x.cudafe2.gpu
# x.cudafe1.cpp