前言
今天突发奇想,体验了一下现在比较热门的AI数字人技术,将最新的几个项目总结一下,大家也可以了解一下数字人技术的最新进展。
EchoMimic
上传人物头像 + 一段语音,生成一段人物说话/唱歌的视频
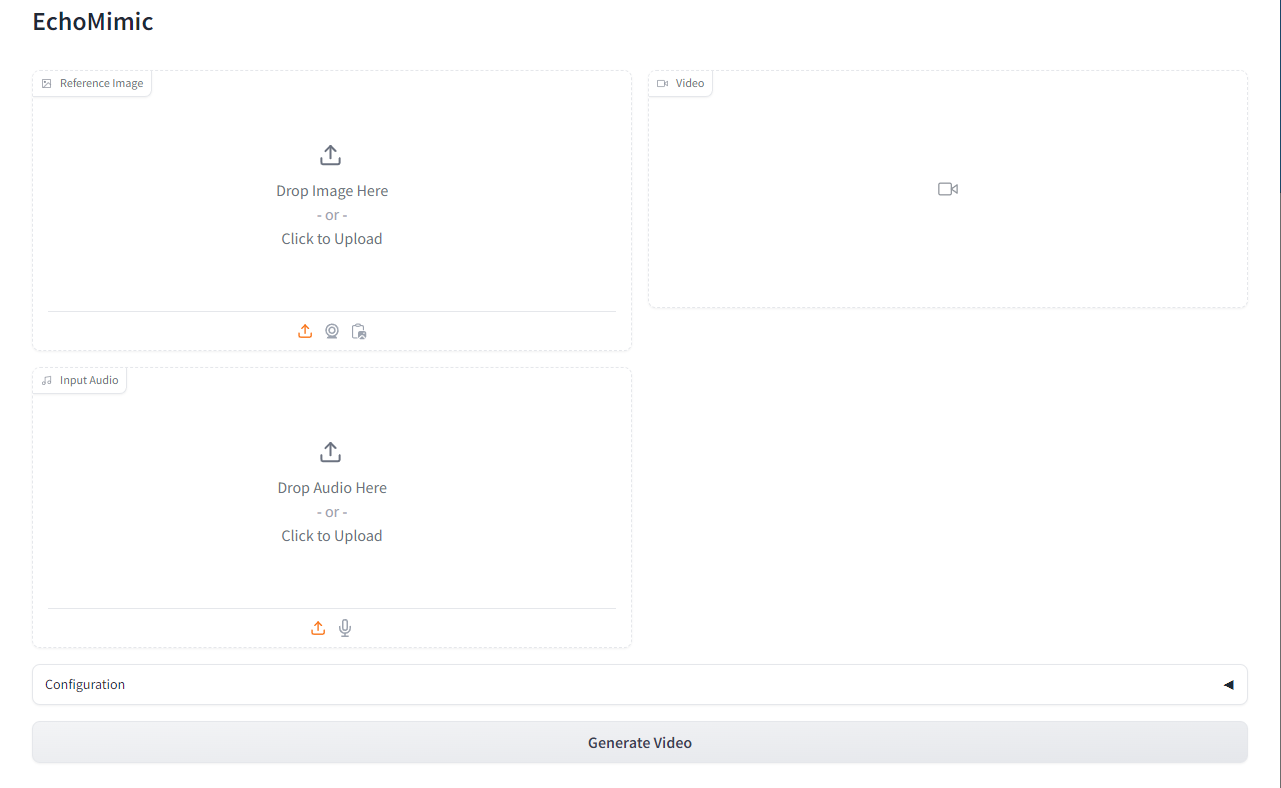


因为不方便放视频,所以我转成了 GIF 格式,猜猜韩老板和丁真说的什么? ![]()
CosyVoice
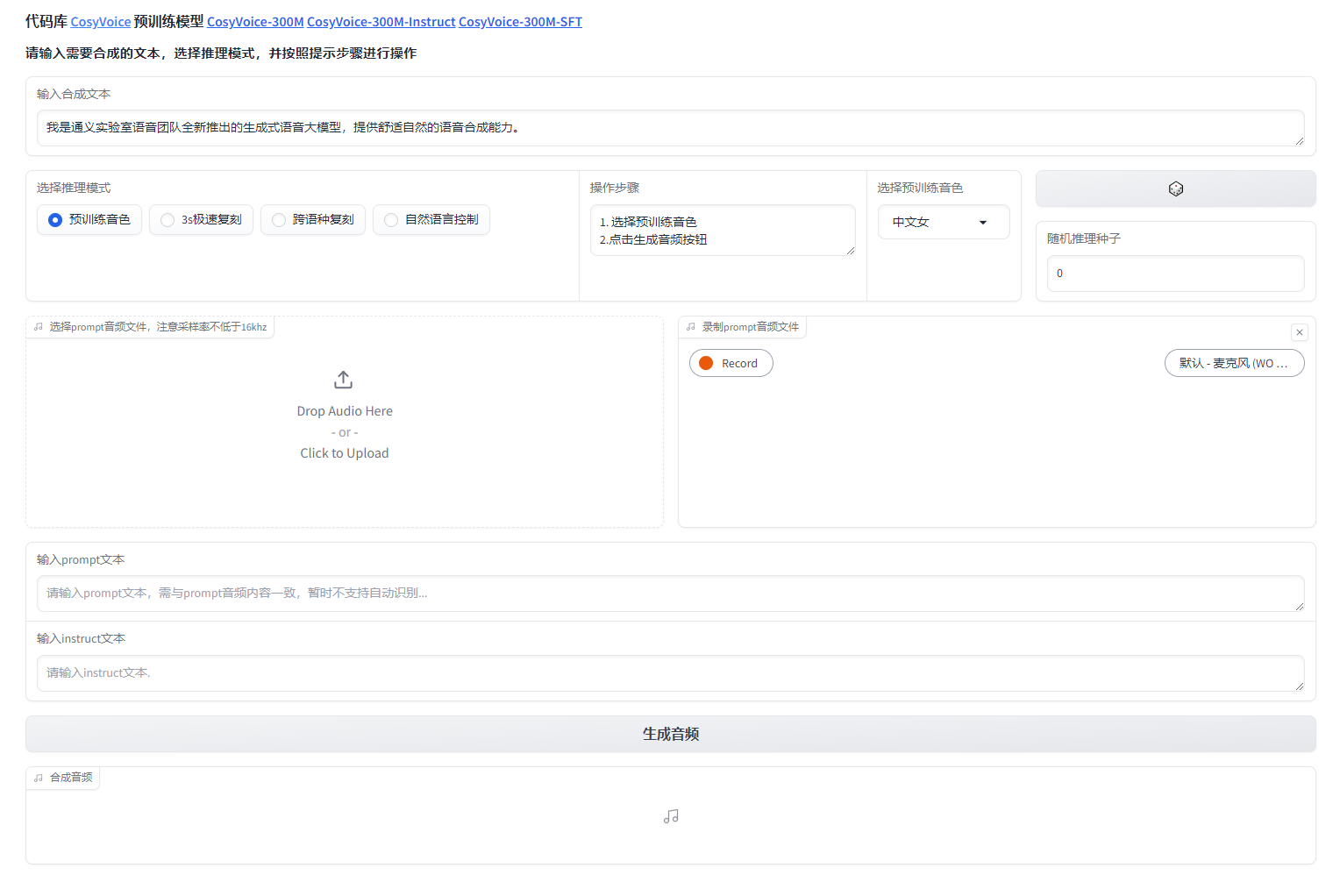
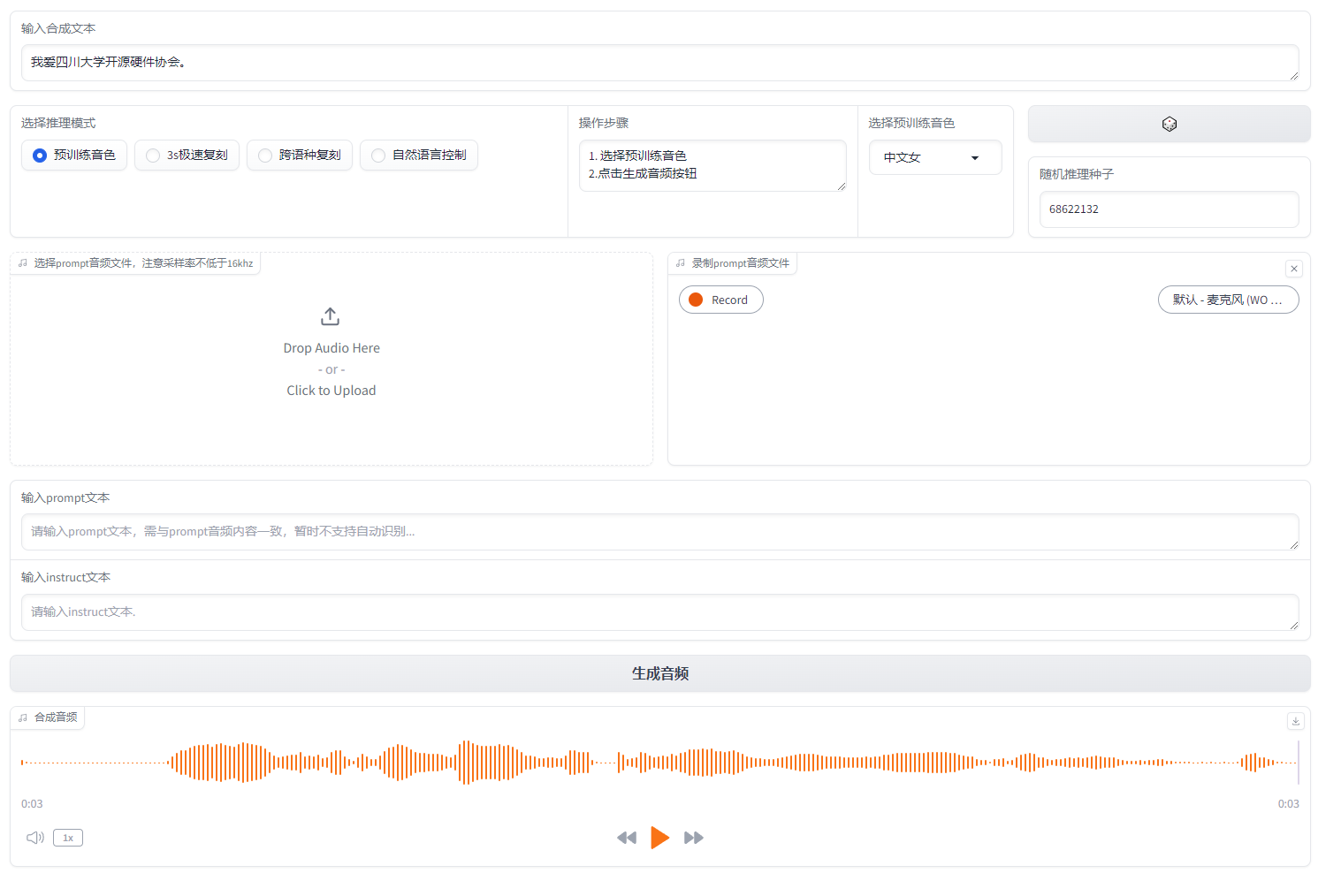
有两种功能:
- 直接用训练好的音色去进行文本转语音
- 上传一段音频(你想要模仿的音色)以及这段音频对应的文本(说的是什么内容),然后再输入你想这个音色说的话,进行模仿生成
注意,所有的输入文本都要以标点符号结尾。
SenseVoice
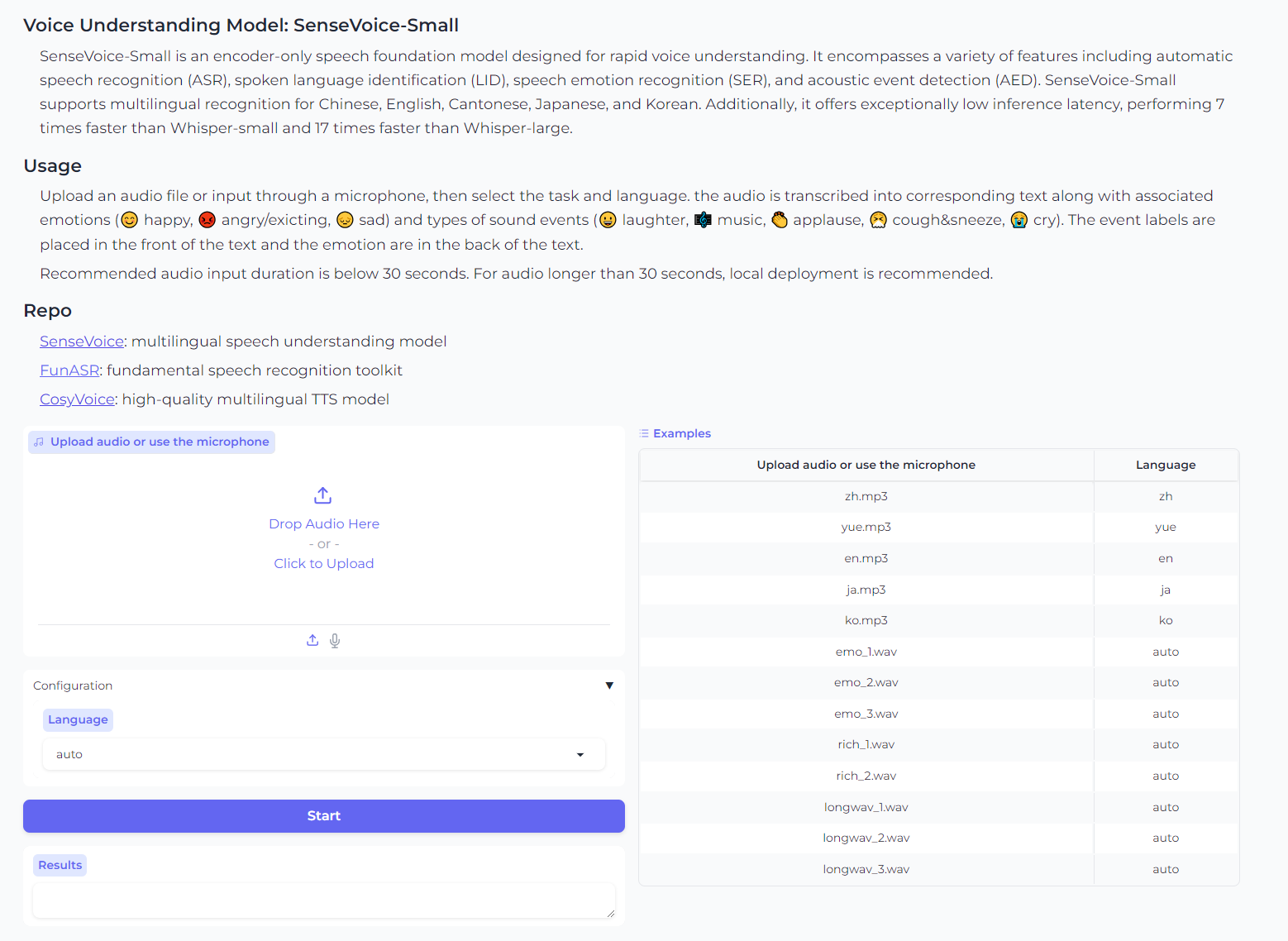
输入一段音频,可以转文字(自动生成字幕),并且可以提取出来其中的情感,在文字中穿插emoji
GPT-SoVITS
核心功能是,根据一个人的音频,来训练模型学这个人说话(数据多可以微调,数据少也可以直接用)。然后给一段文字,用给定音频的音色来进行语音转文字。
- 零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
- 少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
- 跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
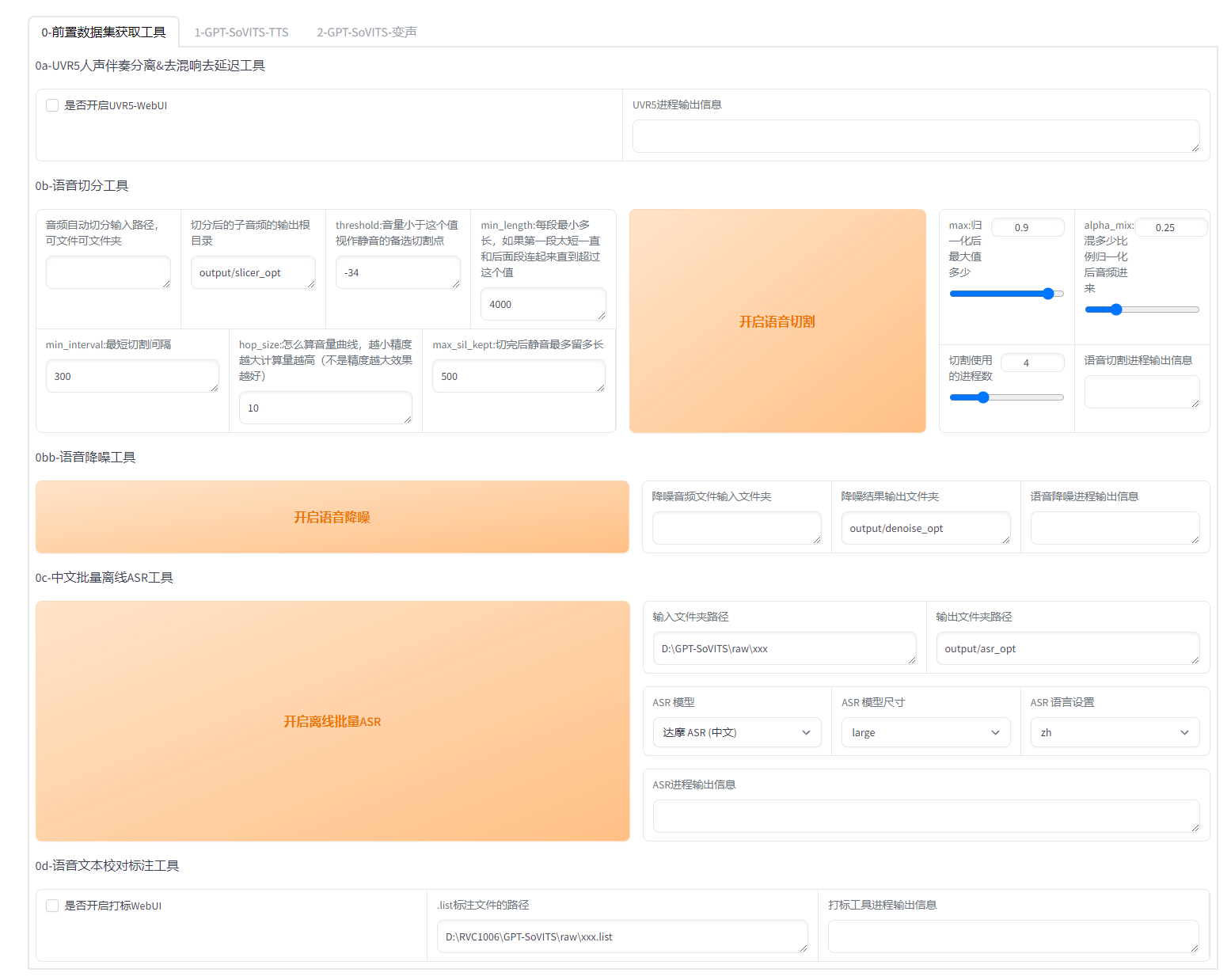
- WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
优点:数据处理的工具很全,基本上都有
缺点:需要的声音数据需要口音标准(例如普通话、标准英语),如果不是,效果不是很好。
RVC
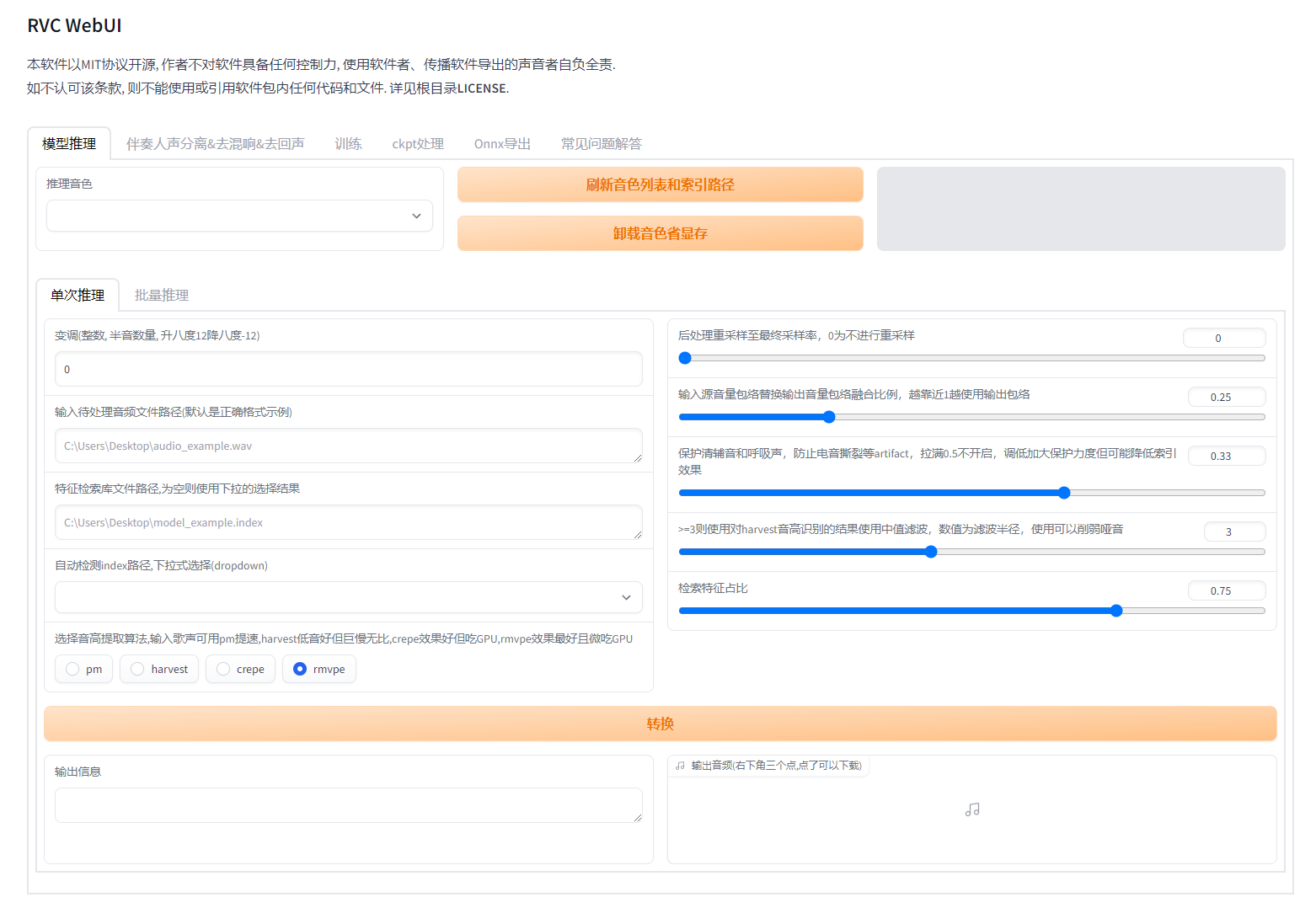
可以通过训练进行语音转语音,而且有配套的语音处理工具。
例如用A的唱歌数据,先进行声音和伴奏的分离,然后用声音训练A的模型,然后把B的歌曲进行声音和伴奏的分离,把B的人声输入到模型里面,替换为A的人声,再和B的伴奏进行合成,就可以生成A唱B的歌的效果。可以用于AI歌手等用途。
