数据结构简介
一 线性数据结构
1.数组(Array)
int array[5];
array[0] = 1;
array[1] = 3;
//
int array[] = {1, 3, 50};
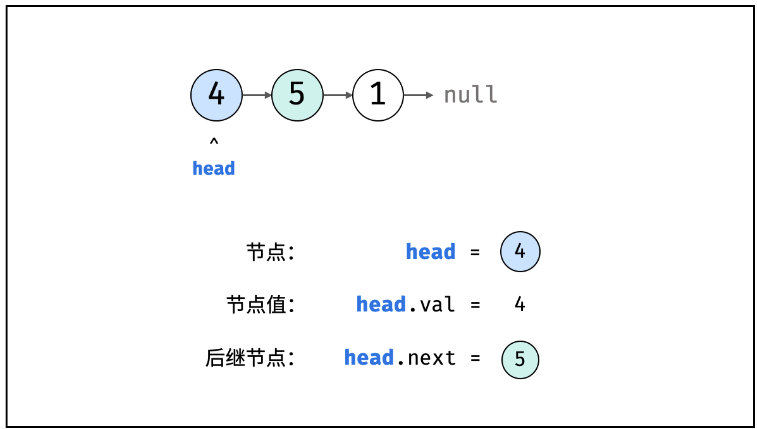
2.链表(Linked List)
struct ListNode {
int val; //节点值
ListNode *next; //节点指针,指向下一个值
ListNode(int x) : val(x), next(NULL) {} //构造函数,初始化列表
};
//实例化
//实例化节点
ListNode *n1 = new ListNode(4);
ListNode *n2 = new ListNode(5);
ListNode *n3 = new ListNode(1);
//创建next指针
n1->next = n2;
n2->next = n3;
class ListNode:
def _init_(self, x):
self.val = x
self.next = None;
# 实例化
#实例化节点
n1 = ListNode(4)
n2 = ListNode(5)
n3 = ListNode(1)
#实例化next指针
n1.next = n2
n2.next = n3
3.栈(Stack)
stack<int> stk;
//入栈出栈
stk.push(2);//元素 2 入栈
stk.push(5);//元素 5 入栈
stk.pop();//元素 5 出栈
stk.pop();//元素 2 出栈
stack = [] #python把列表当栈用
#入栈出栈
stack.append(3)
stack.append(5)
stack.pop()
stack.pop()
4.队列(Queue)
queue<int> que;
//入队出队
que.push(1);
que.push(2);
que.pop();
que.pop();
#python通常使用双端队列 collections.deque
from collections import deque
que = deque()
#入队出队
que.append(1)
que.append(2)
que.popleft()
que.popleft()
二 非线性数据结构
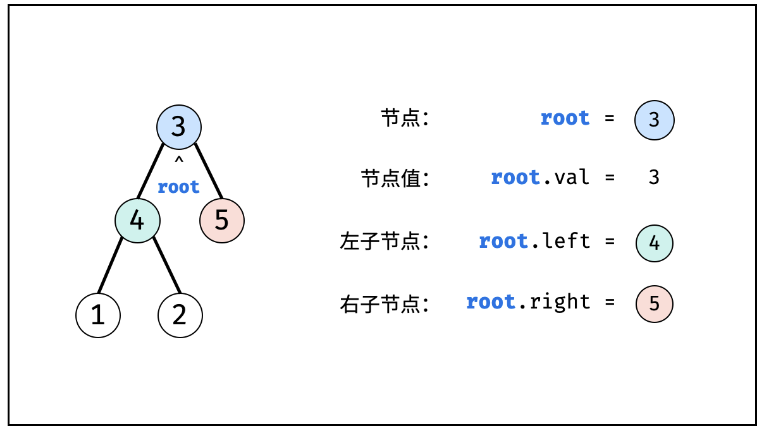
1.树(Tree)
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
// 初始化节点
TreeNode *n1 = new TreeNode(3); // 根节点 root
TreeNode *n2 = new TreeNode(4);
TreeNode *n3 = new TreeNode(5);
TreeNode *n4 = new TreeNode(1);
TreeNode *n5 = new TreeNode(2);
// 构建引用指向
n1->left = n2;
n1->right = n3;
n2->left = n4;
n2->right = n5;
}
class TreeNode:
def _init_(self, x):
self.val = x # 节点值
self.left = None #左子节点
self.right = None #右子节点
#初始化节点
n1 = TreeNode(3)
n2 = TreeNode(4)
n3 = TreeNode(5)
n4 = TreeNode(1)
n5 = TreeNode(2)
#节点引用指向
n1.left = n2
n1.right = n3
n2.left = n4
n2.right = n5
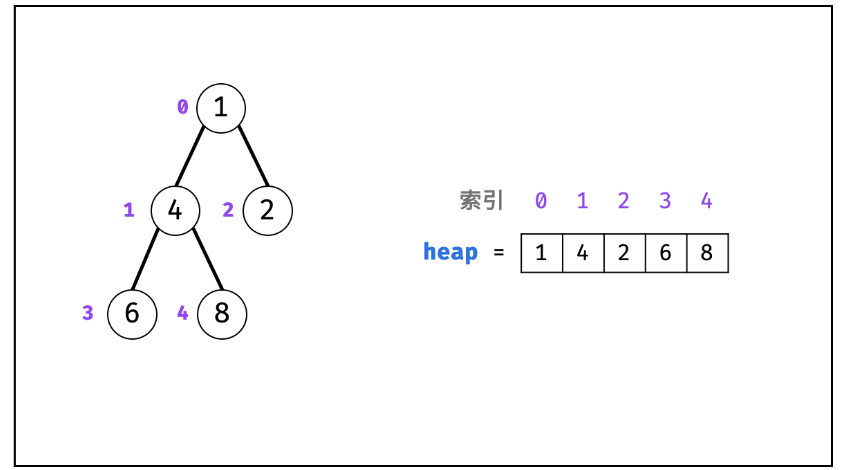
2.堆(Heap)
堆是一种基于「完全二叉树」的数据结构,可使用数组实现。以堆为原理的排序算法称为「堆排序」,基于堆实现的数据结构为「优先队列」。堆分为「大顶堆」和「小顶堆」,大(小)顶堆:任意节点的值不大于(小于)其父节点的值。
**完全二叉树:**在完全二叉树中,除了最后一层可能不是满的,其他每一层从左到右都是满的。如果最后一层存在节点,则这些节点从左到右排列。完全二叉树可以用数组来表示,节点编号从上到下、从左到右依次增加,父节点和子节点之间的关系可以通过数组的索引计算得到。
如下图所示,为包含 1, 4, 2, 6, 8 元素的小顶堆。将堆(完全二叉树)中的结点按层编号,即可映射到右边的数组存储形式。
通过使用「优先队列」的「压入
push()」和「弹出 pop()」操作,即可完成堆排序,实现代码如下:
//初始化最小堆
priority_queue<int, vector<int>, greater<int>> heap;
//往堆中添加元素
heap.push(1);
heap.push(4);
heap.push(2);
heap.push(6);
heap.push(8);
//出堆,每次pop出根节点
heap.pop(); //1
heap.pop(); //2
heap.pop(); //4
heap.pop(); //6
heap.pop(); //8
3.哈希表(Hashing)
暂略
4.图(Graph)
图是一种非线性数据结构,由「节点(顶点)vertex」和「边 edge」组成,每条边连接一对顶点。根据边的方向有无,图可分为「有向图」和「无向图」。
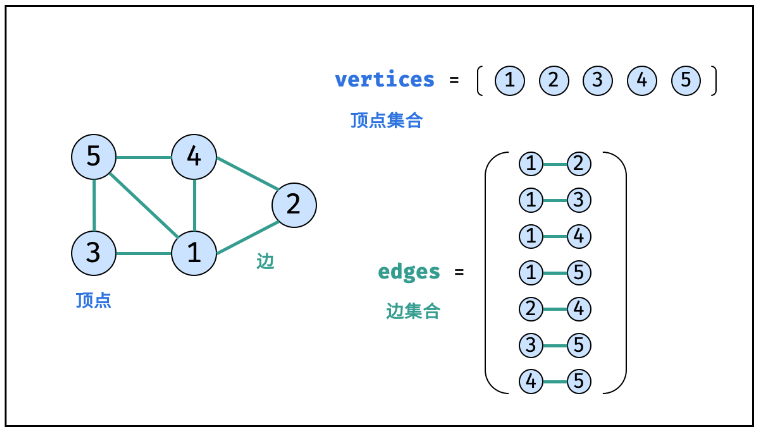
表示图的方法有两种:
邻接表 适合存储稀疏图(顶点较多、边较少); 邻接矩阵 适合存储稠密图(顶点较少、边较多)。
1.邻接矩阵

int vertices[5] = {1, 2, 3, 4, 5};
int edges[5][5] = {{0, 1, 1, 1, 1},
{1, 0, 0, 1, 0},
{1, 0, 0, 0, 1},
{1, 1, 0, 0, 1},
{1, 0, 1, 1, 0}};
vertices = [1, 2, 3, 4, 5];
edges = [[0, 1, 1, 1, 1],
[1, 0, 0, 1, 0],
[1, 0, 0, 0, 1],
[1, 1, 0, 0, 1],
[1, 0, 1, 1, 0]];
2.邻接表

int vertices[5] = {1, 2, 3, 4, 5};
vector<vector<int>> edges;
vector<int> edge_1 = {1, 2, 3, 4};
vector<int> edge_2 = {0, 3};
vector<int> edge_3 = {0, 4};
vector<int> edge_4 = {0, 1, 4};
vector<int> edge_5 = {0, 2, 3};
edges.push_back(edge_1);
edges.push_back(edge_2);
edges.push_back(edge_3);
edges.push_back(edge_4);
edges.push_back(edge_5);
vertices = [1, 2, 3, 4, 5]
edges = [[1, 2, 3, 4],
[0, 3],
[0, 4],
[0. 1. 4],
[0, 2, 3]]
#Python真的好简洁
算法(Algorithm)
一 排序算法
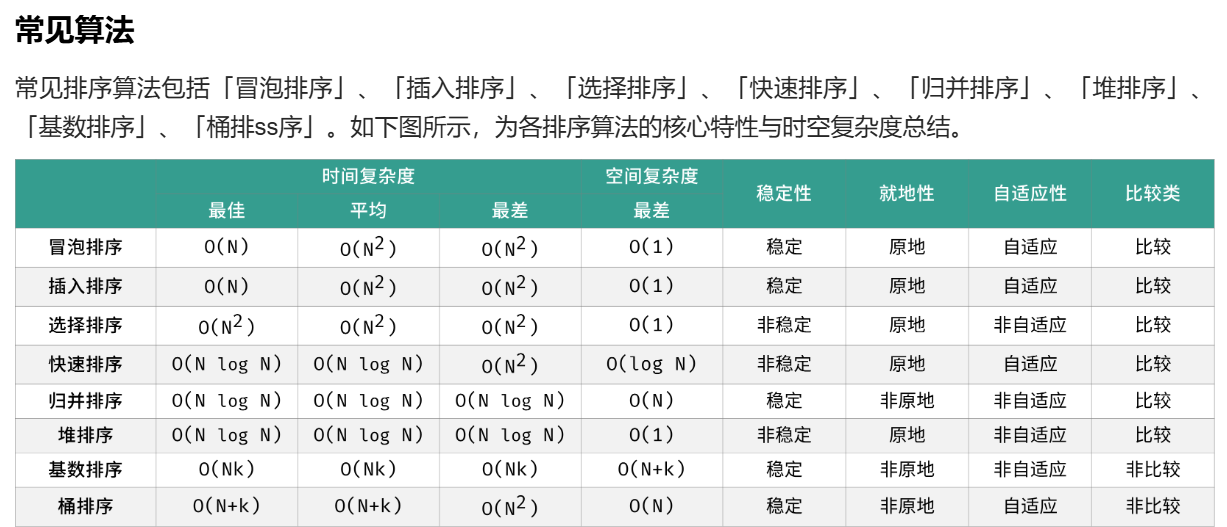
1.冒泡排序
冒泡排序是最基础的排序算法,由于其直观性,经常作为首个介绍的排序算法。其原理为:
- 内循环: 使用相邻双指针 j , j + 1 从左至右遍历,依次比较相邻元素大小,若左元素大于右元素则将它们交换;遍历完成时,最大元素会被交换至数组最右边 。
- 外循环: 不断重复「内循环」,每轮将当前最大元素交换至 剩余未排序数组最右边 ,直至所有元素都被交换至正确位置时结束。
void bubbleSort(vector<int> &nums) {
int N = nums.size();
for (int i = 0; i < N - 1; i++) { // 外循环
for (int j = 0; j < N - i - 1; j++) { // 内循环
if (nums[j] > nums[j + 1]) {
// 交换 nums[j], nums[j + 1]
swap(nums[j], nums[j + 1]);
}
}
}
}
通过增加一个**标志位 flag **,若在某轮「内循环」中未执行任何交换操作,则说明数组已经完成排序,直接返回结果即可。
void bubbleSort(vector<int> &nums) {
int N = nums.size();
for (int i = 0; i < N - 1; i++) {
bool flag = false; // 初始化标志位
for (int j = 0; j < N - i - 1; j++) {
if (nums[j] > nums[j + 1]) {
swap(nums[j], nums[j + 1]);
flag = true; // 记录交换元素
}
}
if (!flag) break; // 内循环未交换任何元素,则跳出
}
}
2.快速排序
快速排序
快速排序算法有两个核心点,分别为哨兵划分 和 递归 。
**哨兵划分:**以数组某个元素(一般选取首元素)为 基准数 ,将所有小于基准数的元素移动至其左边,大于基准数的元素移动至其右边。
void quick_sort(int q[], int l, int r) {
if(l >= r) return;
int i = l-1, j = r+1, x = q[l+r >> 1];//哨兵和基准的选择
while(i < j) {
do i ++; while(q[i] < x);
do j --; while(q[i] > x);
if(i < j) swap(q[i], q[j]);
}
quick_sort(q,l,j), quick_sort(q, j+1, r);
}
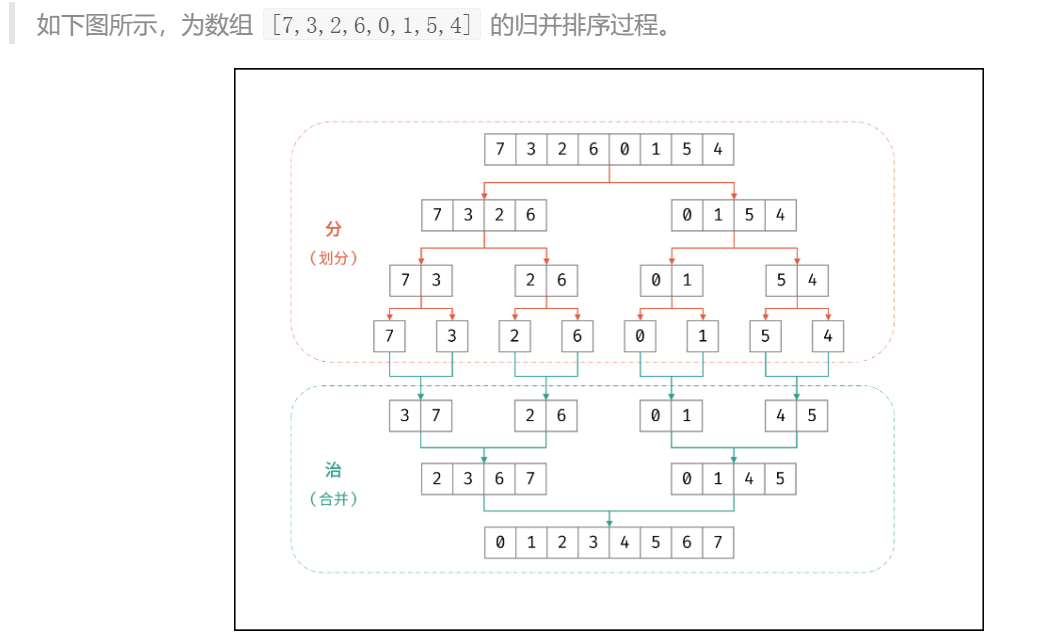
3.归并排序
归并排序体现了“分而治之” 的算法思想,具体为:
-
「分」: 不断将数组从 中点位置 划分开,将原数组的排序问题转化为子数组的排序问题;
-
「治」: 划分到子数组长度为 1 时,开始向上合并,不断将 左右两个较短排序数组 合并为 一个较长排序数组,直至合并至原数组时完成排序;
void mergeSort(vector<int>& nums, int l, int r) {
// 终止条件
if (l >= r) return;
// 递归划分
int m = (l + r) / 2;
mergeSort(nums, l, m);
mergeSort(nums, m + 1, r);
// 合并阶段
int tmp[r - l + 1]; // 暂存需合并区间元素
for (int k = l; k <= r; k++)
tmp[k - l] = nums[k];
int i = 0, j = m - l + 1; // 两指针分别指向左/右子数组的首个元素
for (int k = l; k <= r; k++) { // 遍历合并左/右子数组
if (i == m - l + 1)
nums[k] = tmp[j++];
else if (j == r - l + 1 || tmp[i] <= tmp[j])
nums[k] = tmp[i++];
else {
nums[k] = tmp[j++];
}
}
}
// 调用
vector<int> nums = { 4, 1, 3, 2, 5, 1 };
mergeSort(nums, 0, nums.size() - 1);
void merge_sort(int q[], int l, int r)
{
if(l >= r) return;
int mid = l + r >> 1;
merge_sort(q, l, mid);
merge_sort(q, mid + 1, r);
int k = 0, i = l, j = mid + 1;
while(i <= mid && j <= r)
if(q[i] <= q[j]) tmp[k++] = q[i++];
else tmp[k++] = q[j++];
while(i <= mid) tmp[k++] = q[i++];
while(j <= r) tmp[k++] = q[j++];
for(i = l, j = 0; i <= r; i ++, j++) q[i] = tmp[j];
}
4.其他排序方法(略
附刷题网站:
题库 - 力扣 (LeetCode) 全球极客挚爱的技术成长平台