good!
顺便,翻译了一下原帖,以便于不太了解Docker的人或许可以看看中文翻译来了解一下
标题:使用不到100行Go代码构建自己的容器
URL 来源:Build Your Own Container Using Less than 100 Lines of Go - InfoQ
发布时间:2016-04-22
Markdown 内容:
Docker 在 2013 年 3 月的开源发布引发了软件开发行业在打包和部署现代应用程序方式上的重大转变。在 Docker 的推动下,出现了许多竞争、互补和支持的容器技术,这导致了该领域的热炒和一些失望。本系列文章旨在消除一些混淆,解释容器在企业中的实际使用情况。
本系列文章首先探讨容器背后的核心技术以及开发者目前如何使用这些技术,然后研究在企业中部署容器的核心挑战,例如将容器化整合到持续集成和持续交付流水线中,以及增强监控以支持变化的工作负载和可能的短暂性。系列文章最后展望容器化的未来,讨论 unikernel 在前沿组织中目前扮演的角色。
本文是系列文章“现实世界中的容器 - 走出炒作曲线”的一部分。您可以通过 RSS 订阅以接收通知。
类比的问题在于,它们往往会让你在听到时停止思考。有人可能会说,软件架构“就像”建筑架构。不是的,这个类比听起来不错,但实际上可能造成了不少伤害。类似地,软件容器化常被宣传为能够“就像”运输集装箱运输货物一样移动软件。不完全是。或者说,确实如此,但这个类比丢失了很多细节。
运输集装箱和软件容器确实有很多共同点。运输集装箱以其标准形状和尺寸实现了强大的规模经济和标准化。软件容器也承诺带来许多相同的优势。但这是一个表面类比——是一个目标,而非事实。
要真正理解软件世界中的容器是什么,我们需要了解构建一个容器需要哪些内容。这就是本文要解释的。在这个过程中,我们将讨论容器与容器化、Linux 容器(包括命名空间、控制组和分层文件系统),然后通过一些代码逐步构建一个简单的容器,最后讨论这一切的真正含义。
容器到底是什么?
我想玩一个游戏。现在在你的脑海中告诉我,“容器”是什么。想好了吗?好的。让我猜猜你可能会说些什么:
你可能会提到以下一个或多个:
- 一种共享资源的方式
- 进程隔离
- 有点像轻量级虚拟化
- 将根文件系统和元数据打包在一起
- 有点像 chroot 监狱
- 与运输集装箱有关的东西
- Docker 做的任何东西
一个词承载了这么多含义!“容器”这个词开始被用于许多(有时重叠的)概念。它被用来类比容器化,也被用来指代实现它的技术。如果我们分开考虑这些,就能看得更清楚。所以,让我们先谈谈容器的“为什么”,然后是“如何”。(然后我们会再次回到“为什么”)。
最初的情况
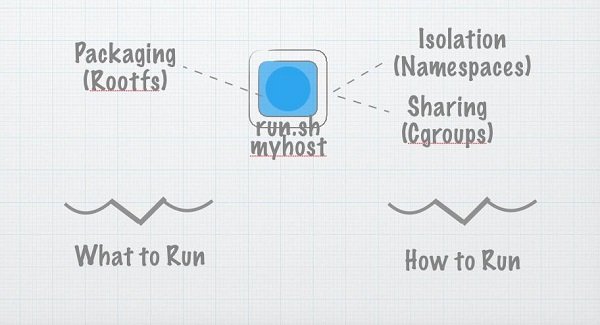
最初,有一个程序。我们叫它 run.sh,我们会把它复制到远程服务器上运行。然而,在远程计算机上运行任意代码不安全,也难以管理和扩展。于是我们发明了虚拟专用服务器和用户权限。事情变好了。
但小小的 run.sh 有依赖项。它需要主机上存在特定的库。而且它在远程和本地运行时从不完全相同。(如果你听过这个说法就打断我)。于是我们发明了 AMI(亚马逊机器镜像)、VMDK(VMware 镜像)和 Vagrantfile 等等,事情又变好了。
嗯,算是好了。这些包很大,难以有效分发,因为它们不够标准化。于是,我们发明了缓存。
事情又变好了。
缓存使 Docker 镜像比 VMDK 或 Vagrantfile 更有效。它让我们可以传输基于某些通用基础镜像的增量,而不是移动整个镜像。这意味着我们可以负担得起将整个环境从一个地方传输到另一个地方。这就是为什么当你运行 docker run whatever 时,即使 whatever 描述了整个操作系统镜像,它也能几乎立即启动。我们将在(第 N 节)中详细讨论其工作原理。
实际上,这就是容器的意义所在。它们是将依赖项打包,以便以可重复、安全的方式传输代码。但这是一个高层次的目标,而不是定义。所以让我们谈谈现实。
构建容器
那么(这次是真的!)容器是什么?如果创建容器就像调用一个 create_container 系统调用那样简单就好了。不是这样。但老实说,也差不多了。
要从底层讨论容器,我们必须谈三件事:命名空间、控制组和分层文件系统。还有其他东西,但这三个构成了大部分魔法。
命名空间
命名空间提供了在一台机器上运行多个容器所需的隔离,同时让每个容器看起来像拥有自己的环境。在撰写本文时,有六种命名空间。每种都可以独立请求,相当于给一个进程(及其子进程)提供机器资源的一个子集视图。
这些命名空间是:
-
PID:PID 命名空间为进程及其子进程提供了系统中进程子集的独立视图。可以将其视为一个映射表。当 PID 命名空间中的进程向内核请求进程列表时,内核会查看映射表。如果进程存在于映射表中,则使用映射的 ID 而不是真实的 ID。如果它不在映射表中,内核会假装它不存在。PID 命名空间使在其中创建的第一个进程成为 PID 1(通过将其主机 ID 映射为 1),从而形成一个隔离的容器进程树。
-
MNT:在某种程度上,这是最重要的。挂载命名空间为其中的进程提供了自己的挂载表。这意味着它们可以挂载和卸载目录,而不影响其他命名空间(包括主机命名空间)。更重要的是,结合 pivot_root 系统调用——正如我们将看到的——它允许进程拥有自己的文件系统。这就是我们如何让进程认为它运行在 Ubuntu、Busybox 或 Alpine 上的方式——通过更换容器看到的文件系统。
-
NET:网络命名空间为使用它的进程提供了自己的网络栈。通常,只有主网络命名空间(计算机启动时进程使用的那个)会真正连接到物理网卡。但我们可以创建虚拟以太网对——连接的以太网卡,一端放在一个网络命名空间,另一端放在另一个,从而在网络命名空间之间创建虚拟链接。就像一台主机上有多个 IP 栈相互通信。通过一些路由魔法,这允许每个容器与现实世界通信,同时将其隔离在自己的网络栈中。
-
UTS:UTS 命名空间为其进程提供了系统主机名和域名的独立视图。进入 UTS 命名空间后,设置主机名或域名不会影响其他进程。
-
IPC:IPC 命名空间隔离了各种进程间通信机制,如消息队列。有关更多详情,请参阅 命名空间 文档。
-
USER:用户命名空间是最近添加的,从安全角度看可能是最强大的。用户命名空间将进程看到的 UID 映射到主机上的另一组 UID(和 GID)。这非常有用。使用用户命名空间,我们可以将容器的根用户 ID(即 0)映射到主机上的任意(无特权的)UID。这意味着我们可以让容器认为它具有根权限——甚至可以在容器特定资源上实际赋予它类似根的权限——而实际上在根命名空间中不授予任何特权。容器可以自由以 UID 0 运行进程——这通常等同于拥有根权限——但内核实际上在幕后将该 UID 映射到无特权的真实 UID。大多数容器系统不会将容器中的任何 UID 映射到调用命名空间中的 UID 0:换句话说,容器中根本没有具有真正根权限的 UID。
大多数容器技术会将用户进程放入上述所有命名空间,并初始化这些命名空间以提供标准环境。例如,在容器的隔离网络命名空间中创建初始网卡,并与主机上的真实网络连接。
控制组(CGroups)
控制组本身可以写一整篇文章(我保留写一篇的权利!)。我在这里会简要介绍,因为一旦你理解了概念,文档中可以找到很多信息。
从根本上说,控制组将一组进程或任务 ID 收集在一起,并对它们应用限制。命名空间隔离进程,而控制组在进程间强制执行公平(或不公平——由你决定,随意发挥)的资源共享。
控制组由内核作为特殊文件系统暴露出来,你可以挂载它。通过将进程 ID 添加到任务文件中,你可以将进程或线程添加到控制组,然后通过编辑该目录中的文件来读取和配置各种值。
分层文件系统
命名空间和控制组是容器化的隔离和资源共享方面。它们是大金属侧板和码头上的保安。分层文件系统是我们能够高效移动整个机器镜像的原因:它们是让船漂浮而不是沉没的原因。
在基本层面上,分层文件系统优化了为每个容器创建根文件系统副本的调用。有多种方法可以实现这一点。Btrfs 在文件系统层使用写时复制。Aufs 使用“联合挂载”。由于实现这一步骤的方法有很多,本文将使用一个极其简单的方法:我们将真正进行复制。很慢,但有效。
构建容器
第一步:搭建骨架
让我们先搭建一个粗略的骨架。假设你已安装最新版本的 Go 编程语言 SDK,然后打开编辑器,复制以下代码。
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
parent()
case "child":
child()
default:
panic("wat should I do")
}
}
func parent() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
}
}
func child() {
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
}
}
func must(err error) {
if err != nil {
panic(err)
}
}
这段代码做什么?我们在 main.go 中读取第一个参数。如果是“run”,则运行 parent() 方法;如果是“child”,则运行 child 方法。parent 方法运行 /proc/self/exe,这是一个包含当前可执行文件内存映像的特殊文件。换句话说,我们重新运行自己,但将“child”作为第一个参数传递。
这是什么疯狂的操作?目前,没什么大不了的。它只是让我们执行另一个程序,该程序执行用户请求的程序(通过 os.Args[2:] 提供)。有了这个简单的脚手架,我们就可以创建容器。
第二步:添加命名空间
要在程序中添加一些命名空间,只需添加一行代码。在 parent() 方法的第二行,添加以下代码,告诉 Go 在运行子进程时传递一些额外的标志。
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
现在运行程序,你的程序将在 UTS、PID 和 MNT 命名空间中运行!
第三步:根文件系统
目前,你的进程处于一组隔离的命名空间中(你可以尝试在此处将其他命名空间添加到 Cloneflags 中)。但文件系统看起来与主机相同。这是因为你处于挂载命名空间中,但初始挂载是从创建命名空间继承的。
让我们改变这一点。我们需要以下四行简单代码来切换到根文件系统。将它们放在 child() 函数的开头。
must(syscall.Mount("rootfs", "rootfs", "", syscall.MS_BIND, ""))
must(os.MkdirAll("rootfs/oldrootfs", 0700))
must(syscall.PivotRoot("rootfs", "rootfs/oldrootfs"))
must(os.Chdir("/"))
最后两行是关键部分,它们告诉操作系统将当前目录 / 移动到 rootfs/oldrootfs,并将新的 rootfs 目录切换到 /。在 pivotroot 调用完成后,容器中的 / 目录将指向 rootfs。(绑定挂载调用是为了满足 pivotroot 命令的一些要求——操作系统要求 pivotroot 用于交换不在同一树中的两个文件系统,通过将 rootfs 绑定挂载到自身来实现这一点。是的,挺傻的)。
第四步:初始化容器的世界
此时,你有一个运行在隔离命名空间集中的进程,拥有你选择的根文件系统。我们跳过了设置控制组,尽管这很简单,我们也跳过了根文件系统管理,这让你可以高效下载和缓存我们 pivotroot 到的根文件系统镜像。
我们还跳过了容器设置。你这里有一个在隔离命名空间中的全新容器。我们通过切换到 rootfs 设置了挂载命名空间,但其他命名空间具有默认内容。在真正的容器中,我们需要在运行用户进程之前为容器配置“世界”。例如,我们需要设置网络,在运行进程之前切换到正确的 UID,设置我们想要的任何其他限制(例如丢弃能力和设置资源限制)等等。这可能会让我们超过 100 行代码。
第五步:整合
这是一个超级简单的容器,用(远少于)100 行 Go 代码实现。显然,这是故意简化的。如果你在生产环境中使用它,你疯了,而且更重要的是,你得自己承担后果。但我认为,看到一些简单且粗糙的东西能真正帮助理解发生了什么。让我们来看看清单 A。
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
parent()
case "child":
child()
default:
panic("wat should I do")
}
}
func parent() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
}
}
func child() {
must(syscall.Mount("rootfs", "rootfs", "", syscall.MS_BIND, ""))
must(os.MkdirAll("rootfs/oldrootfs", 0700))
must(syscall.PivotRoot("rootfs", "rootfs/oldrootfs"))
must(os.Chdir("/"))
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println("ERROR", err)
os.Exit(1)
}
}
func must(err error) {
if err != nil {
panic(err)
}
}
这意味着什么?
在这里,我要提出一些争议性的观点。对我来说,容器是一种以低成本、良好隔离的方式传输和运行代码的绝佳方式,但这不是讨论的终点。容器是一项技术,而不是用户体验。
作为用户,我不想在生产环境中手动推送容器,就像在 amazon.com 上购物的消费者不想亲自打电话到码头安排货物运输一样。容器是构建优秀平台的基础技术,但我们不应该被移动机器镜像的能力分散注意力,而忽略了构建真正出色开发者体验的需要。
基于容器的平台即服务(PaaS),如 Cloud Foundry,以代码而非容器为基础提供用户体验。对于大多数开发者来说,他们想要的是推送代码并让它运行。在幕后,Cloud Foundry——以及大多数其他 PaaS——会获取代码并创建容器化镜像,进行扩展和管理。在 Cloud Foundry 的情况下,这使用了一个构建包,但你也可以跳过这一步,直接推送从 Dockerfile 创建的 Docker 镜像。
通过 PaaS,容器的所有优势依然存在——一致的环境、高效的资源管理等——但通过控制用户体验,PaaS 既能为开发者提供更简单的体验,还能执行一些额外的操作,如在发现安全漏洞时修补根文件系统。此外,平台还提供数据库和消息队列等服务,你可以绑定到你的应用程序,无需将一切都视为容器。
所以,我们已经探讨了容器是什么。现在,我们该用它们做什么?
END