介绍协议本身还是太枯燥了。官方有非常好的实践教程 ,可以先跑一遍。仓库 ,直接 vs code 启动,断点看看代码是怎么工作的。这个教程好就好在启动成本很低,能非常顺利的搭建一个实例插件,启动插件和语言服务器。
跑完这个教程,你就可以在样例工程里改改写写,尝试 LSP 的各种功能了。想知道有哪些能力,查官方文档 是必不可少的。
但是语言服务非常重交互,而协议本身数据驱动,只靠文字是很单薄的,难以描述出提供的用户交互体验,初学者只看干巴巴的接口定义肯定会头晕,不知道这些接口都能干什么。不过也不怪 LSP 官方,毕竟只负责设计协议,具体的实现还得靠客户端(各大编辑器)。
这时候就推荐曲线救国了:先去看看 VS Code 内置 API 教程。作为来自客户端编写的教程,文档全面,内容生动。可以很轻量的快速实现小功能,验证想法。系列第一章 了解语言服务器架构如何解决这些问题)
可以先看语义高亮 教程,了解如何通过原生 API 给每个变量上色。
接着,非常推荐这篇文档 ,它列出了原生 API 和 LSP 的对应关系。毕竟 VS Code 和 LSP 一样都是微软家的,同根同源,深度集成,很多概念和术语都相通。
文档里详细讲解了 VS Code 支持的语言特性,并且都配上了动图和聊胜于无的文字说明。要说为什么是聊胜于无,还是因为交互太重了,各个功能需要多写 demo 去体验,意会。
从学习和方便调试的角度,可以尝试先用 VS Code API 实现一些功能,翻翻 API 的文档,然后再换成 LSP 实现,两者的文档交叉比对,能更好的体会“设计”和“实现”的差异,更好的理解 LSP。
最后,一定要克隆这个仓库 ,它覆盖了大部分使用原生 API 实现智能编程的例子。当你的代码没有正常工作,一定要来看看示例怎么写的。
本文会多次提到“客户端”、“编辑器”、“VS Code”等词,事先澄清,避免混淆:
在 VS Code 这个软件中,编辑器指负责用户交互,能显示、编辑代码的区域,也就是 monaco 编辑器 。
再次正式介绍一下,LSP 是指 Language Server Protocol,语言服务器协议。
所谓协议,是规定了两端通信的数据格式、交互方式。
\r\n
{
"jsonrpc": "2.0",
"id": 1,
"method": "textDocument/completion",
"params": {
...
}
}
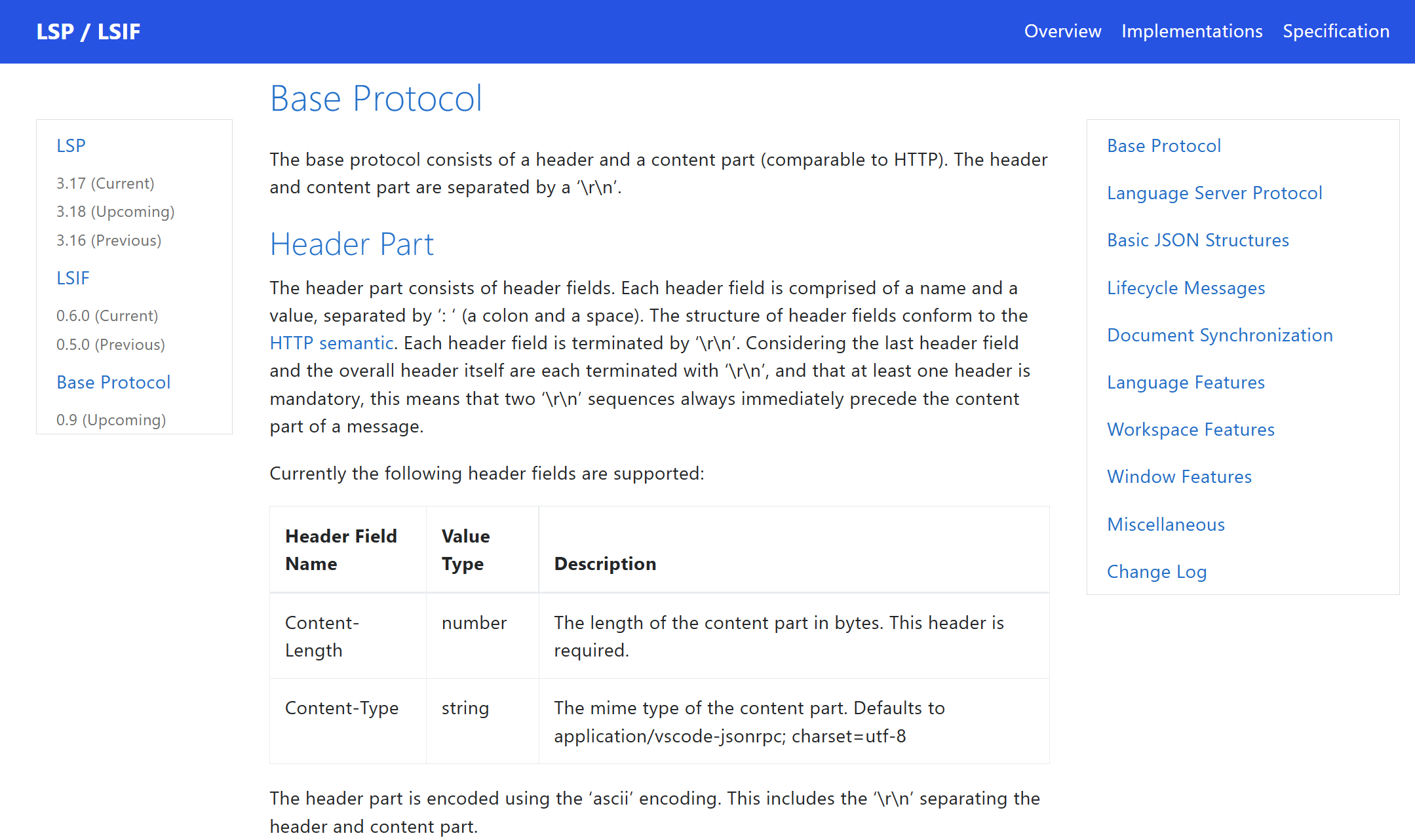
与 HTTP 类似,LSP 消息也分 Header 和 Body 两部分。
Content-Length 是 Header 其中一个字段,和 HTTP 一样,代表 Body 的长度。
LSP 使用 JSON-RPC 格式描述消息内容,包括请求和响应。简单来说就是一段 utf-8 编码的 JSON 字符串,好处是简单和平台无关。
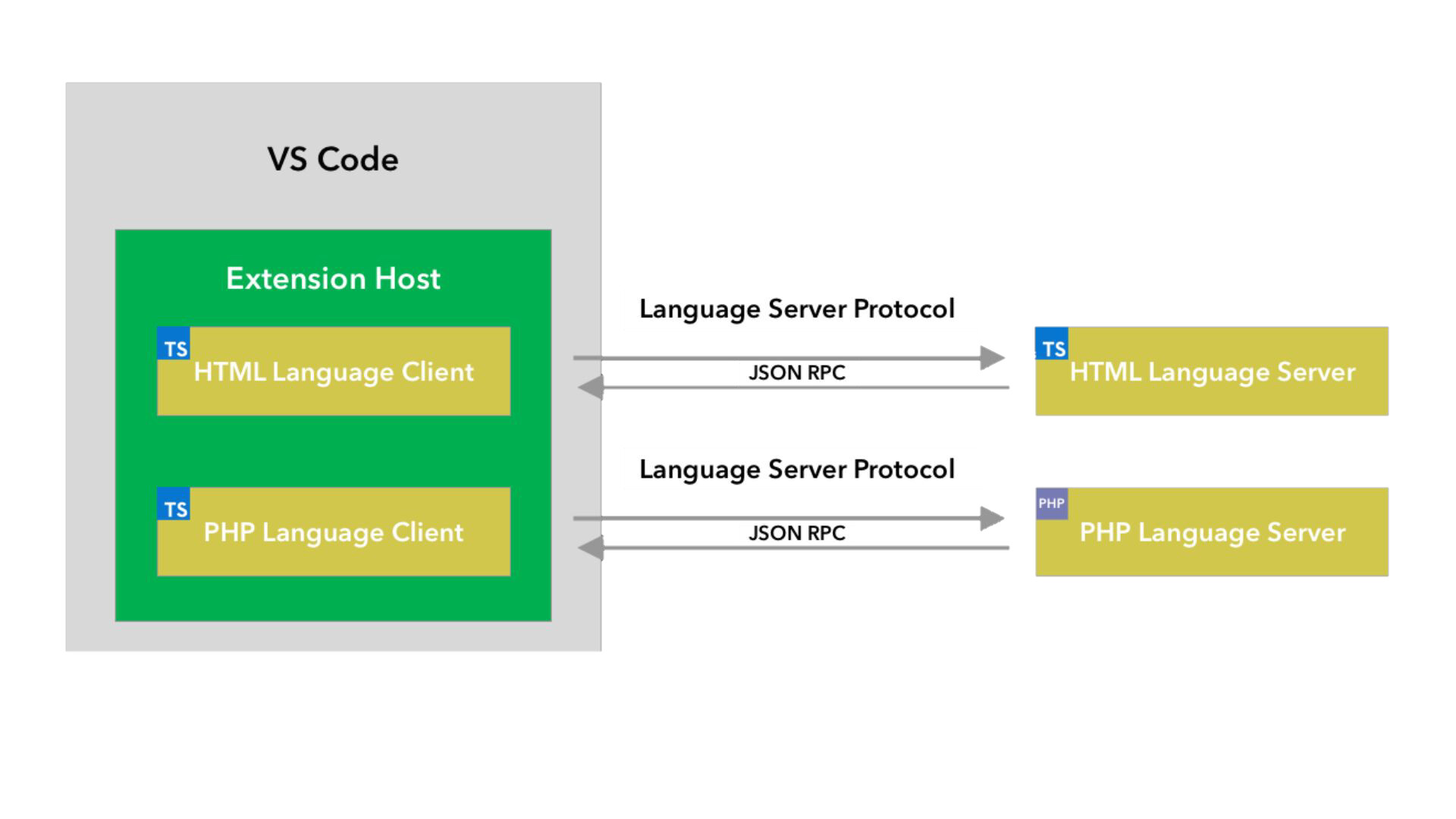
本质上,语言服务器与客户端通信,是进程间通信。常见的方式有 stdio、ipc、pipe、socket 等。VS Code 插件承担了客户端的角色,在官方的 client SDK 中支持了全部这四种通信方式。具体可以见文档这里 。
本质上,LSP 通信就是两个进程之间的通信。一个进程是语言客户端,对应到 VS Code 里,就是插件的进程(Extension Host),然后由它启动语言服务器进程。语言服务器架构 就讲过,BetBrains 仅支持部分功能。例如一个语言服务器提供了全量的语义高亮功能,以及(出于性能原因)按行号范围高亮的功能,后者对于成千上万行的用户文本非常重要,但一些编辑器就是不支持后者的,只支持语言服务器提供整个文件范围的高亮。
这里会有一个坑点 :协议规定了客户端如果收到服务器发来的,自己不理解的功能,可以忽略它 。这本身没有问题,是为了客户端更健壮,至少此时不应该有 exception,但会增加开发者的调试难度。Inlay Hints 能力,两端都能非常顺利的启动、运行,但无论如何编辑器中就是不渲染服务器发过来的 hints。原因就是客户端静默处理了自己不认识的 Inlay Hints 能力,服务器费力编译好算出数据发给客户端,客户端直接丢掉不用了。解决方法就是升级客户端代码,让它支持更新的协议版本。
在这之后初始化已完成,就可以交换数据了。客户端会有几个关键的事件,来推进整个通信流程,比如打开、编辑、关闭、删除、新增、重命名文档等等。高亮 、诊断 、悬浮提示 信息等等,这样编辑器里就从白纸黑字升级了。接下来,用户按下键盘输入代码,在编辑过程中服务器会提供代码补全 、签名提示 等服务,用户输入完成后,防抖式的重新编译当前文件,更新高亮、诊断等。
语言服务器是不是可以仅完整编译打开了的文件,而只预编译其他没打开的文件呢?答案是否定的。
预编译主要解决了循环引用的问题:在 X 代码块中引用了 Y,在 Y 代码块中由又引用了 X,只要仅编译签名,可以绕过编译代码块,理清依赖关系。这又是语言服务器和编译器工作方式的相似之处。
处理频繁的、无征兆的用户输入是实现语言服务器的一大难点。在用户按键输入的时候,一方面,用户希望立即得到代码补全提示,其中可能包括当前作用域的变量、函数、类等;另一方面,一行代码也许得等到用户输入到最后一个分号 ; 时才是没有语法错误的。前者需要快速响应,后者需要容错,这往往是矛盾的。
为了性能,语言服务器往往通过防抖的方式,在用户输入完一段时间(例如 200ms)后再编译,更新语义模型。这些智能编程功能中,用户对延迟的敏感度是不一样的。想象一下,你在输入一行代码时,高亮更新慢一些、报错信息晚一点出现,似乎都还可以接受。但如果代码补全的列表迟迟不出现,那就非常痛苦了。没有人想一个一个字母的输入一个冗长的变量名对吧,你想手动打出 This_Is_A_Very_Looong_Variable_Name 吗?更多的时候是希望输入 This 之后一个 Tab 就把剩下的 31 个字母都补全了对吧。这是代码补全功能的最大挑战:如何在容错的前提下快速响应用户输入。后边会在具体的功能中详细说明。
另外,为了加速编译,语言服务器可以实现一个高级特性,就是“增量编译”,只更新用户输入改变了的语义模型。可能的实现方式是,如果用户输入只改了一个代码块里的代码,就只更新这一部分的语义模型,而不是完全重新编译。
好了,接下来会聊聊生动有趣的部分,也是最干的部分:具体的请求和我踩过的坑。
initialize这是第一个请求,由客户端发到服务器。服务器可以将自身信息(名字、版本号)还有支持的能力发给客户端。也可以声明每个功能的具体细节。
capabilities: {
hoverProvider: true, // 悬浮提示
semanticTokensProvider: {
// 语义高亮
full: false,
range: true,
legend: {
tokenTypes: [],
tokenModifiers: [],
},
},
completionProvider: {
// 代码补全
triggerCharacters: [".", '"', "<", "#"],
},
signatureHelpProvider: {
// 签名提示
triggerCharacters: ["(", ","],
},
definitionProvider: true, // 跳转到定义
inlayHintProvider: true, // 内联提示
},
};
这里注意,这个请求是由客户端发向服务端的。服务端声明的,是由客户端发起 的请求的支持情况,不包括服务器主动推给客户端的。"(" "," 来触发 signature help。
textDocument/didOpen 和改动文件 textDocument/didChange两个最基础的文件同步请求,客户端发起,服务端接收。
didChange 请求还可以将(一个或多个)具体改动 也告知语言服务器,便于语义信息的增量更新等。比如只是删除了一个函数中的一行,也许就不用重新编译作用域内的其他函数。
textDocument/completion随着用户键盘输入,客户端会向语言服务器发送代码补全请求,获取信息后在光标旁渲染一个补全列表。
VS Code 里下拉框的内容是语言服务器给出的数据的超集 。这个下拉框里还包括代码片段(snippet) ,和 VS Code 自带的补全已有输入的内容。
客户端可能会对列表数据重新排序,例如 VS Code,因此语言服务器也许不需要按字典序返回,省一些性能。
代码补全是可以做的非常深的功能。
var foo = 0
while (true) {
var bar = 1
// 补全 foo、bar,忽略 zee
if true {
var zee = 2
}
}
}
在第 5 行输入时,由于语义 要求,应该补全当前作用域以及上层作用域的变量,忽略下层作用域。
这带来一个问题,获取语义信息 就意味着需要经过语法分析和语义分析,而你可以想象一下,输入一行代码的过程中,几乎只有最后一个分号写完,这个代码才可能是没有编译错误的。
另外,用户编码时,代码补全如果延迟很高,这会非常痛苦(我想读者们肯定碰到过代码写着写着补全消失的时候),但由于性能原因,语言服务器的更新编译经常是防抖的,也就是在用户停止输入一段时间后再编译,这意味着拿到语义信息有延迟。
这就是代码补全的两个难点:处理容错、以及延迟和性能的矛盾。
这里和具体的语法分析方案相关,我给出一些基于 antlr 做词法分析、语法分析的经验。
首先 antlr 有非常出色的容错能力,即使代码中有语法错误,也可以尽可能解析出正确代码的语法。undefined、nil 问题)
但有时候补全往往是和当前这一行相关的,依然需要这一行有错误的代码的语义信息。例如 console. 补全 log warning error 函数。补全项要基于已经输入的代码来异化。
有两个解决的方向,优化语法和从词法尝试推断语法和语义。
从语法上,设计更宽容的语法结构,允许一些看上去“没有意义”的代码出现。例如,允许一个属性单独成行,没有读操作也没有写操作。
foo: 1,
bar: {
bar1: true,
bar2: "",
},
};
x.bar; //.bar1
大多数情况下,x.bar 单独成行在运行时是没有什么意义的(除非 bar 是一个 getter 函数)。但对于语言服务器,好处是在最后一行输入 x.bar 后,不会有语法错误,再输入点号 .,语言服务器能根据上次的编译结果(即还没有输入点时)得知左侧是一个对象,进而补全 bar1、bar1 两个属性。
还有一个艰难的方法,无法借助词法分析工具,就手动分析残缺的词法,推测可能的语法。
// ^ 光标在此
对于这行代码,必然有语法错误,但 antlr 可以分析出这一行的 token:光标前有一个 DOT,再往前是一个 IDENTIFIER。
当然,语法结构层出不穷,通过回溯 TOKEN 推测可能的语法结构是一件复杂的事情。
这里推荐这个库 antlr-c3 ,是专门针对基于 antlr4 的语法分析时,做自动补全的引擎。它会基于语法文件(parser.g4),尝试预测可能的语法节点是什么。
textDocument/semanticTokens高亮最好理解了,就是给白底黑字的代码上色。这是一个非常复杂、容易出现性能问题的功能。
这也是和客户端表现高度相关的功能,先讲讲 VS Code 的高亮系统。一行代码哪里显示蓝色,哪里显示黄色?token。token 会有类型 type,这一定程度上代表了它的语义,例如关键字、类、枚举等。type 是决定 token 颜色的核心。颜色主题系统 ,可以通过 JSON 配置每个 type 的渲染颜色、样式,维护数据 和表现 的映射关系。
"scope": "keyword", // 关键字
"settings": {
"foreground": "#ff007f",
"fontStyle": "bold"
}
}
这样即使用户切换颜色主题,只需要切换样式即可,比如从亮色模式转为深色模式,但无需重新解析 token。
除了 type,还有一个 modifier 的概念,它也会影响 token 的渲染,但只是一种修饰,不是必要的。modifier 来实现,不过这就取决于具体的颜色设计了。
脱离 LSP,VS Code 有一个轻量的无需编程的、基于正则的高亮系统,与语义无关,被称为语法 高亮
刚才说到 VS Code 的高亮首先要将文本分段为 token,这其实也是一个词法分析的过程(Tokenization)。方式就是正则表达式,通过正则匹配,基于词法和语法,做简单的高亮,具体的配置规则被称为 tmLanguage 或者 Textmate grammars。
TypeScript 就有一个规模惊人的配置文件 。这种文件实在是人类太不可读了,我的建议是要灵活借助 AI 的力量,让 LLM 根据需求生成配置还是比较顺利的。
几个坑点是,tmLanguage.json 采用严格的 json 语法,不能有注释,否则,配置的任何高亮在 VS Code 中都不会生效。想存注释的话,可以手写一个自定义字段来实现。在调试时建议使用官方的检查器 ,来确认匹配结果。
如果配置文件格式正确,检查器也显示成功匹配(token type 符合预期),但依然没有高亮,那么可以切换颜色主题试试,可能是因为当前颜色主题的色彩太少了,很多 token 就是默认的颜色。
这就低成本实现了简单的高亮。
在2025年的1月版本中(1.97 ),VS Code 官方开始尝试用 Tree-Sitter 代替 tmLanguage,用词法、语法分析替换单纯的正则匹配。理由是许多 tmLanguage 都不再维护了。
有了 VS Code 的例子,理解 LSP 中的高亮就不困难了。客户端会在某些时机向语言服务器请求高亮数据,服务器返回一个个 token,包括位置、type、modifier 等,客户端自行决定如何渲染。
这是客户端主动发起的请求,在 initialize 请求中,需要一些配置,例如下边这种。一点一点解释:
full: {
delta: true,
},
range: true,
legend: {
tokenTypes: ["method","property","string", ...],
tokenModifiers: ["readonly","async","static", ...],
},
}
这个配置有点复杂,如果配的有问题,客户端的高亮会无静默失效,服务器似乎不会收到报错。一行行解释:
所谓的 legend,是用来声明 token 有哪些 type、modifier。他们实际上是两个字符串数组,例如 type 可能是 ["method","property","string", ...] 。token?如果完整的渲染每一行,浪费不说(用户一次只会看一些行),性能也有巨大的压力。token 是一个有序的列表,在中间行改动就意味着它后边的所有 token 都得变化,在算法上也有挑战。
为此 LSP 为数据通信做了简单的编码来降低通信的流量。具体的编码方式可以看官方的文档 ,简单来说就是将位置、type、modifier编码为 5 个整数,通信时不再用明文的 "method" "property" 等。
另外 LSP 还提出两个优化,增量更新(full/delta)和范围渲染(range)。token 时,只在首次请求 textDocument/semanticTokens/full 中返回全量的 token,之后发送 textDocument/semanticTokens/full/delta 请求,语言服务器需要根据文件变化,计算出比起上一次返回的 token 有哪些差异,返回增量部分。token。请求是 textDocument/semanticTokens/range。因此,语言服务器最好按照文本字符流的顺序收集 token,这样每次请求无需遍历所有的 token,到范围外就可以截断了。
此外,这个请求由客户端发起,这意味着服务端不可控。打开文件、滚动屏幕、调整窗口大小,都会引起这个请求,这个相对好处理。
Vue 的语言服务器 使用了简单粗暴,但是非常有效的方式:仅支持范围高亮,并且收到请求后固定等待一段时间,比如 200ms 后再响应。
textDocument/inlayHint
这是用来快速浏览信息的功能,通常会用来显示函数定义时形式参数的名字等。否则这个信息需要悬浮提示或者跳转到定义才能拿到,不过也有人会觉得这个提示太干扰,所以最好做成用户可配置关闭的。静默失败 ,没有报错。
textDocument/signatureHelp
写函数调用时,输入左括号 ( 时弹出的信息,这就是签名提示。这时候用户会想看到函数的签名信息,包括形式参数的名字、类型,甚至函数返回值等。
麻烦在于输入左括号 ( 时还会有一个请求,也就是文件改动 textDocument/didChange,引起防抖处理和重新编译。通常要等编译完成,才能正确的知道具体是针对哪个函数,来获取其签名信息。didChange 和 signatureHelp 的时序问题,因为由用户输入触发的签名提示的相应,依赖编译完成,使用最新的语义信息(旧的状态是没有意义的)。而请求都是由客户端发出的,具体哪个请求会先发出呢?咨询官方 ,结论是用户键入后,客户端应该确保 didChange 先发送到服务器,然后再请求 signatureHelp,也就是说服务器处理 signatureHelp 请求时一定能获取到最新的客户端状态,以及最新的语义信息。
用户输入后,一定要等防抖以及编译后才能响应,这意味着一定的延迟。但也有一种非常轻量的情况,按方向键也可以触发 signatureHelp,比如光标扫过一个个实际参数时,提示的形式参数的高亮也要改变。
这时候就不用等编译了,因为输入没有改变,只需要根据光标位于哪一个实际参数,高亮形式参数。didChange 和 signatureHelp 是两个独立的请求,语言服务器怎么知道一次 signatureHelp 请求是由方向键响应的呢?
还记得前面说 didChange 请求会提供文本的版本号吗,它可以作为输入是否改变的依据。记录每一次 didChange 的版本号,如果两次 signatureHelp 请求之间版本号没有变化(变大),那么输入就没有变化。
代码补全时,如果用户选择(resolve)了一个函数,一些语言的服务器会将调括号 () 一起补全,例如 Go。
最好的体验是补全后立即触发 signature help,因为这个时候用户就是想要填实际参数,想知道参数数量和类型。triggerParameterHints,Go 的插件确实是这么做的
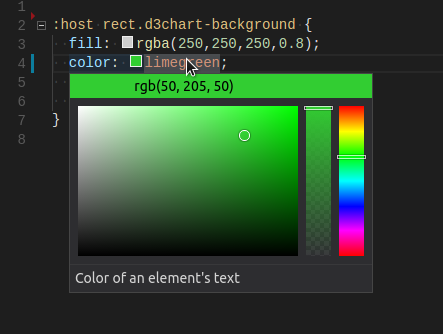
如果语法简单,非常适合在前一章提到的语法的(而非语义的)服务器上解析。例如仅支持井号 # 加十六进制这种语法。
但 css 中那种支持 rgba、十六进制甚至直接颜色名称 red 的语法,就不适合了。
textDocument/publishDiagnostics
这是指把编译错误和警告显示在编辑器里的功能。在 VS Code 里,主要表现为红色、橙色的波浪线。
除了波浪线,诊断还有两种额外的表现 Unnecessary 和 Deprecated,标记没有引用到的字段,和弃用的字段。
/**
* Unused or unnecessary code.
*
* Clients are allowed to render diagnostics with this tag faded out
* instead of having an error squiggle.
*/
export const Unnecessary: 1 = 1;
/**
* Deprecated or obsolete code.
*
* Clients are allowed to rendered diagnostics with this tag strike through.
*/
export const Deprecated: 2 = 2;
}
在 VS Code 里会表现为颜色变浅和删除线。
如果代码里有个字段暂时没法删掉,但又不想有新代码用到,就可以标为废弃,这样同事写出这行代码就会出现删除线,吓他一跳。
Unnecessary 和 Deprecated 的表现其实很像是高亮的行为,影响了代码渲染。deprecated
readonly = "readonly",
static = "static",
deprecated = "deprecated",
//...
}
实际上 VS Code 中很多删除线都是由诊断而不是高亮实现的。官方说法 是,语言服务器不会具体规定客户端的表现,而是由客户端自行决定渲染。对 VS Code 来说,DiagnosticTag 比 SemanticTokenModifiers 出现的更早,因此客户端支持更好。















{kind=link}