码农基本功 - 字符集和编码
基本概念
我们在使用计算机时,主要阅读并关注字符串中的数字、英文字符、中文字符、Emoji 表情等,但是计算机并不关注字符串的单个字符到底是什么意思,因为计算机最终存储和传输的都是二进制比特数据。
所以这里先来看下字符、字符集、编码等基本概念。
字符
人类肉眼可以阅读的最小书写单元:字母、数字、标点、汉字、符号、Emoji 表情等。
码点 (数字)
每个字符分配的唯一整数编号。
字符集
字符和码点 (数字) 的映射关系。
编码(编码方案)
如何设计和实现字符集的 “映射关系”。
ASCII
首先来看看 ASCII 编码。
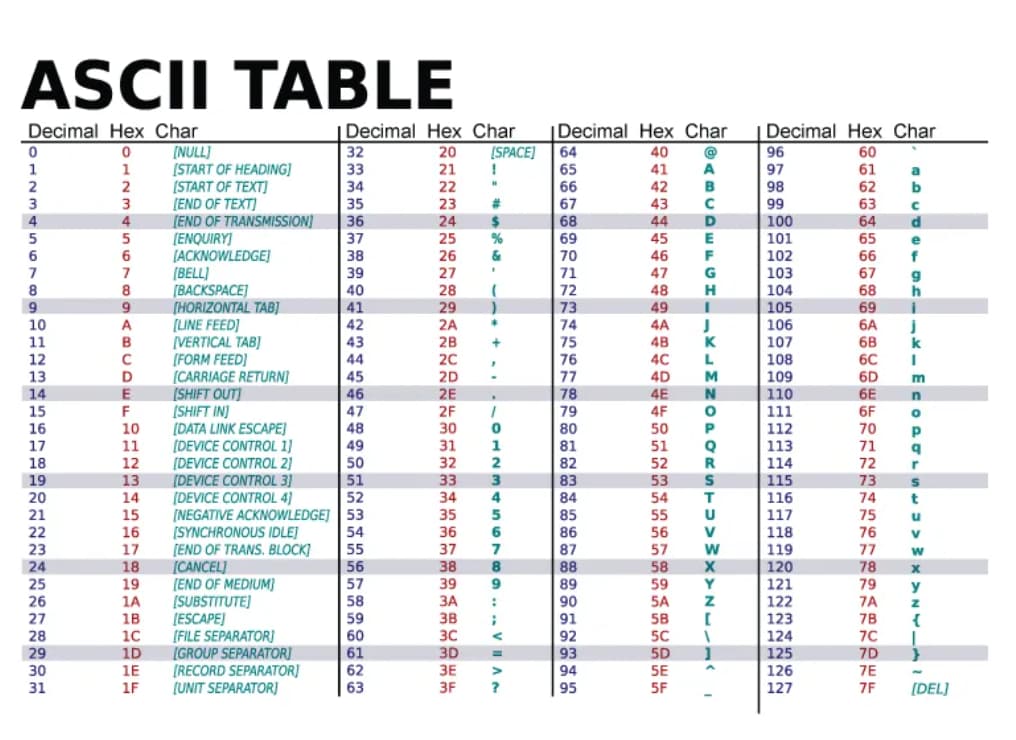
ASCII 是最早期的 使用 1 个字节 (byte) ,7 位 (bit) 编码,最高位始终为 0,来表示常见的英文字符、阿拉伯数字、标点符号和控制符号等。
基本上,你在键盘上面看到的字符,都是 ASCII 字符,使用 0 - 127 表示。

因为编码范围是固定的,所以主流编程语言都内置了 ASCII 字符和数字互相转化的 API,例如在 Python 中,可以通过 ord 和 chr 两个函数来获取数字与 ASCII 字符的对应关系。
# 获取数字与 ASCII 字符的对应关系
print(ord('A')) # 65
print(chr(65)) # 'A'
再比如,我们可以快速获取到小写字母 a-z 对应的数字:
for x in range(ord('a'), ord('z') + 1):
print(x, chr(x))
局限性
对于语言为英文的计算机用户来说,ASCII 编码已经基本够用了,但是对于非英文用户来说,ASCII 编码所能表示的字符太有限了!例如,对于中文用户来说,单单汉字就不止 128 个,还有像日本、韩国等其他有自己语言的国家用户来说,ASCII 编码也存在同样的问题。
此外,还有像 Emoji 表情等更加个性化的符号,要作为字符本身进行传递,ASCII 编码同样无能为力。
理想中的编码方案
为了解决 ASCII 编码的不足,理想情况下,应该设计一个可以包含世界上所有国家语言的字符编码方案,这样不同的国家都可以采用一种编码方案。
同时,用户无需关注和编码相关的系统设置等 (例如使用不同的语言需要进行不同的编码设置)。
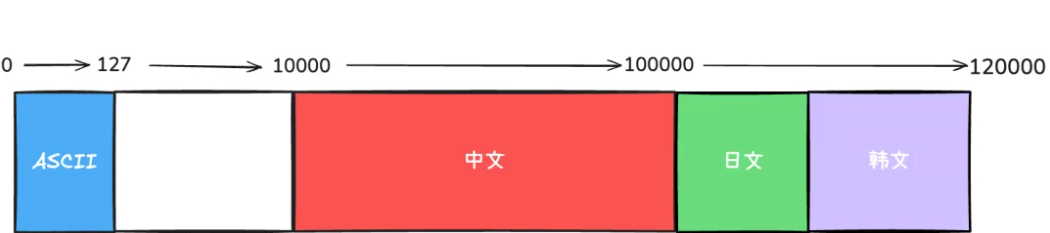
最后,为了兼容已有的 ASCII 编码,其他国家可以在 ASCII 编码的基础上进行延续,各自使用不同的 “数字区间” 来表示对应的字符。
例如,ASCII 编码 使用 0 - 127 来表示,那么其他国家的语言编码方案可以简单设置为:
-
中文使用 10000 - 100000 来表示
-
日文使用 100000 - 110000 来表示
-
韩文使用 110000 - 120000 来表示
-
以此类推
Unicode
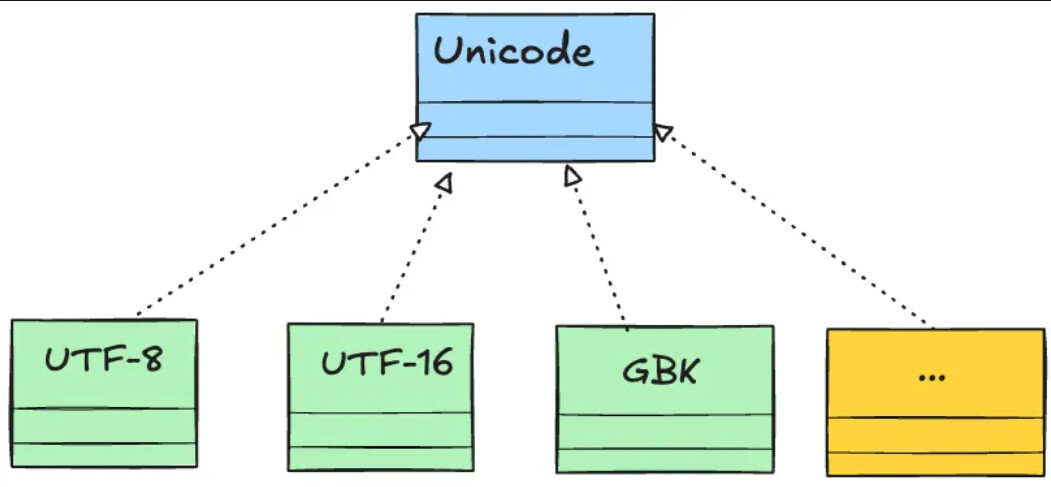
为了解决 ASCII 编码表现能力不足的问题,由 The Unicode Standard 开发了一套业界标准字符集/编码方案,为每种语言中的每个字符设定了唯一的二进制编码,并且跨语言、跨平台,这也就是 Unicode 全球字符集编码方案,简称 Unicode。
具体到实现细节来说,Unicode 又可以分为 编码方式 和 实现方式 两个层次:
-
编码方式 (标准/接口):Unicode 使用数字范围
0-0x10FFFF来映射世界上不同国家的所有字符,最多可以表示 1114112个 字符 -
实现方式 (具体实现):每个字符和对应的数字之间如何互相转换,例如汉字的
中固定使用数字20013来表示,但是中和 20013,这两者之间的转换方式可以由不同的方式来完成,例如 UTF-8、UTF-16、UTF-32 等等
从代码的视角来看,Unicode 是接口,UTF-8 是具体实现。
下面是一些字符转换为 Unicode 对应编码 (数字) 的 Python 代码示例。
def main():
# 输出 Unicode 中对应的唯一数字 (也就是码位) print(ord('中')) # 20013
print(ord('😀')) # 128512
print(ord('A')) # 65
print(ord('a')) # 97
print(ord('1')) # 49
# 输出 Unicode 编码 (十六进制) 表示 print(hex(ord('中'))) # 0x4e2d
print(hex(ord('😀'))) # 0x1f600
print(hex(ord('A'))) # 0x41
print(hex(ord('a'))) # 0x61
print(hex(ord('1'))) # 0x31
局限性/问题
Unicode 虽然为每个字符分配了唯一的 (数字) 编号,但是它本身仅定义字符和数字的映射关系,并没有指定数字在计算机中的存储和传输方式 (二进制表示),这时候,就需要有专门的编码方案来实现 Unicode 提出的标准 (接口)。
UTF-8
最为人熟知的 Unicode 编码实现方案就是 UTF-8 了,除此之外,还有 UTF-16 和 UTF-32,以及仅针对中文字符编码的 GBK 和 GB2312。
虽然每种编码格式都有自己的特点和使用场景,但 UTF-8 因其高效性和兼容性成为互联网最常用的编码方式 ,几乎所有的现代操作系统、主流编程语言和应用程序开发都支持并且默认使用 UTF-8。
UTF-8 成功背后的原因
1. 向后兼容
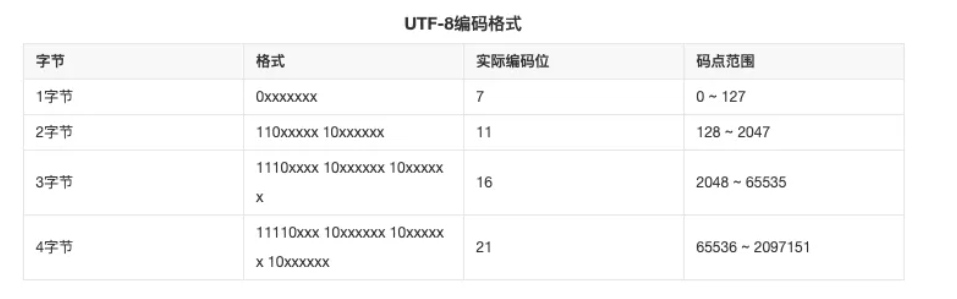
UTF-8 采用可变长度编码方式,对 ASCII 字符只用 1 个字节表示,而对其他字符则使用 2、3 或 4 个字节,具有向后完全兼容 ASCII 的优势。
2. 空间效率优化
对 ASCII 字符只用 1 个字节表示,而对其他字符则使用 2、3 或 4 个字节,不会造成任何存储空间的浪费。
def main():
# UTF-8 使用 1 个字节表示英文 print(len("ab".encode('utf-8'))) # 2 print(len("12".encode('utf-8'))) # 2
# UTF-8 使用 3 个字节表示中文
print(len("中文".encode('utf-8'))) # 6
# UTF-8 使用 4 个字节表示 Emoji 表情 print(len("🙂".encode('utf-8'))) # 4
3. 可扩展性
UTF-8 可以表示所有 Unicode 字符,包括未来可能新出现的字符,例如新出现的字符超出了目前 Unicode 指定的标准范围,那么只需要做两件事情就可以在完全兼容已有字符的前提下,去开发新的字符:
-
Unicode 对于新字符制定新标准 (新字符对应的数字)
-
UTF-8 使用更多变长字节来表示新字符即可 (例如一个新字符使用 5 个字节来表示)
乱码
讲完了 ASCII、Unicode、UTF-8,再来顺带讲一个,乱码符号: � 。
� 其实是 Unicode 定义的一个有效字符,其具体表示方式为:
U+FFFD “replacement character” �
在 Python 中,我们可以直接输出:
def main():
# 第一种方式
print("\uFFFD") # �
# 第二种方式
print(chr(0xFFFD)) # �
在 Python 中,当解码器遇到无法解析的字节时,会插入此字符以保证字符串有效性,而不会直接报错,保证解码过程不会中断。当然,除非手动指定 errors 参数的值设置 ‘strict’。
print(text.decode('utf-8', errors='strict')) # 涓�鏂�
大多数开发者肯定都遇到过的乱码符号:� ,例如常见的业务场景:网络数据传输、数据库服务器/客户端数据传输、网页爬虫数据解析。
这背后的本质原因就是: 解码和编码使用了不同/不兼容的字符集编码方案 ,导致某些字符无法映射到目标编码字符集中的有效码点 (数字),于是被强制替换为 �。
下面使用一个小例子进行说明。
def main():
"""
原始数据使用 UTF-8 编码
解码时却使用 GBK
通过将 errors 参数的值设置为 replace
最终输出乱码 """
s = "中文".encode('utf-8') print(s.decode(encoding='gbk', errors='replace')) # 涓�鏂�
除此之外,部分编程语言截取一部分中文字符时,也会出现乱码符号,例如在 Go 语言中,截断中文字符时,就会出现乱码,下面是一个对应的示例代码。
package main
func main() {
// 因为字符串中有中文,所以这种方式会出现乱码:
s := "Go 语言的优势是什么?"
s2 := s[2:5]
println(s2) // �
}
所以说,理解了编码规则,自然也就理解了为什么会出现乱码。
检测字符串编码工具类
不同字符的可以支持多种编码方式,我们可以通过程序来检测字符支持的编码方式,下面是一个 Python 的实现示例代码。
def detect_supported_encodings(text):
"""
检测给定的 Unicode 字符串支持的编码实现
"""
encodings = ['ascii', 'utf-8', 'gbk', 'big5', 'latin-1']
supported = []
for encoding in encodings:
try:
# 如果编码成功,加入支持结果集
text.encode(encoding)
supported.append(encoding)
except UnicodeEncodeError:
continue
return supported
def main():
# 测试不同字符集的兼容性
print("ASCII字符兼容性:", detect_supported_encodings("Hello World!"))
# ['ascii', 'utf-8', 'gbk', 'big5', 'latin-1']
print("中文字符兼容性:", detect_supported_encodings("中文"))
# ['utf-8', 'gbk'] (GBK 可编码常见汉字)
print("Emoji兼容性:", detect_supported_encodings("😊"))
# ['utf-8'] (只有 UTF-8 支持 Emoji)
小结
-
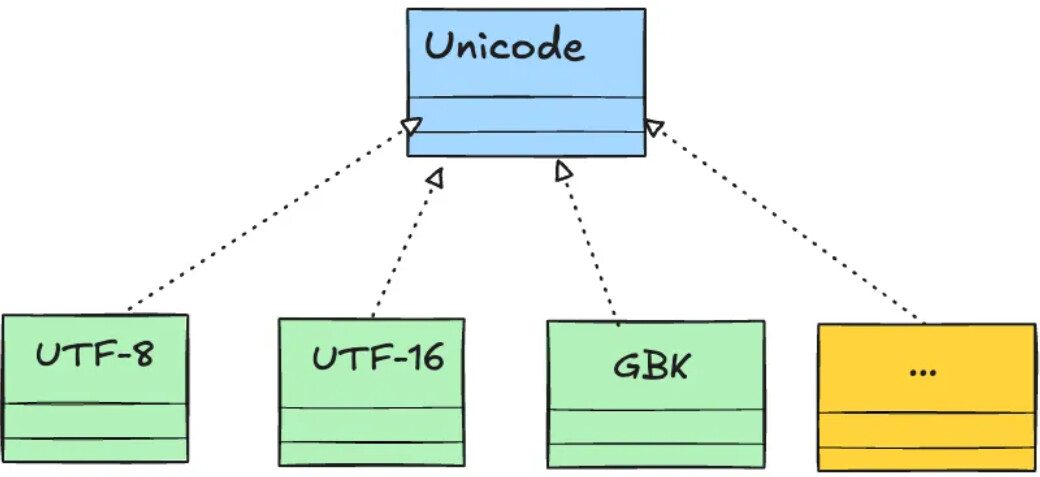
Unicode 是一个编码字符集标准,规定每个字符和码点 (数字) 的唯一映射关系,无法直接用于存储和传输
-
UTF-8 提供了一种完全兼容、效率优化、可扩展的字符编码实现方式,并成为互联网/软件领域的默认字符编码方式
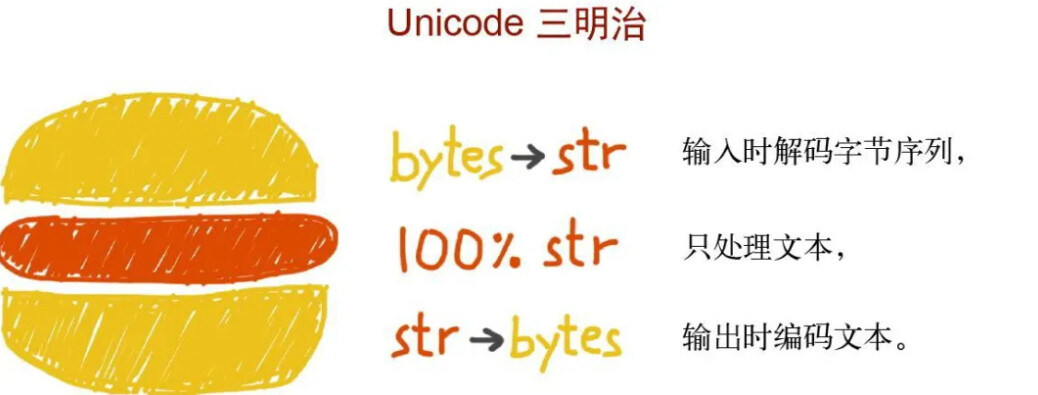
最后,有个 Unicode 三明治原则 ,可以作为大多数应用程序开发的最佳实践。