https://verl.readthedocs.io/en/latest/index.html
verl is a RL training library initiated by ByteDance Seed team and maintained by the verl community.
https://verl.readthedocs.io/en/latest/index.html
verl is a RL training library initiated by ByteDance Seed team and maintained by the verl community.
Source:Config Explanation — verl documentation
data:
tokenizer: null
train_files: ~/data/rlhf/gsm8k/train.parquet
val_files: ~/data/rlhf/gsm8k/test.parquet
prompt_key: prompt
max_prompt_length: 512
max_response_length: 512
train_batch_size: 1024
return_raw_input_ids: False # 当策略和奖励模型的 tokenizer 不同时,应设置为 true
return_raw_chat: False
return_full_prompt: False
shuffle: True
filter_overlong_prompts: False
filter_overlong_prompts_workers: 1
truncation: error
image_key: images
custom_cls:
path: null
name: null
data.train_files:训练集 parquet 文件。可以是单个文件或文件列表。程序会将所有文件读入内存,因此文件不能太大(< 100GB)。路径可以是本地路径或 HDFS 路径。对于 HDFS 路径,提供工具将其下载到 DRAM 并将 HDFS 路径转换为本地路径。data.val_files:验证集 parquet 文件。可以是单个文件或文件列表。data.prompt_key:数据集中存储提示的字段,默认为 ‘prompt’。data.max_prompt_length:最大提示长度。所有提示将左填充到此长度,若长度过长会报错。data.max_response_length:最大回复长度。RL 算法(如 PPO)生成的最大长度。data.train_batch_size:不同 RL 算法一次训练迭代的批次大小。data.return_raw_input_ids:是否返回未添加聊天模板的原始 input_ids。主要用于奖励模型和策略的聊天模板不同时,需先解码后应用奖励模型的聊天模板。若使用基于模型的奖励模型,且策略和奖励模型的聊天模板不同,需设置此标志。data.return_raw_chat:是否返回未应用聊天模板的原始聊天(提示)。data.return_full_prompt:是否返回应用了聊天模板的完整提示。data.shuffle:是否在数据加载器中打乱数据。data.filter_overlong_prompts:默认不过滤超长提示。data.filter_overlong_prompts_workers:对于大规模数据集,过滤超长提示可能耗时,可设置此参数以使用多进程加速,默认值为 1。data.truncation:若 input_ids 或提示长度超过 max_prompt_length,则截断。默认为 ‘error’,不允许超过最大长度,用户需增加 max_prompt_length。也可设置为 ‘left’ 或 ‘right’。data.image_key:多模态数据集中存储图像的字段,默认为 ‘images’。自定义数据集扩展已为 SFT 训练器实现,并可通过类似更改扩展到其他训练器。
custom_cls:
path: null
name: null
data.custom_cls.path:包含自定义数据集类的文件路径。若未指定,使用预实现的.dataset。data.custom_cls.name:指定文件中数据集类的名称。actor_rollout_ref:
hybrid_engine: True
model:
path: ~/models/deepseek-llm-7b-chat
external_lib: null
override_config:
model_config: {}
moe_config: # 仅限 Megatron,可调整 moe 配置
freeze_moe_router: False # 仅限 Megatron,可冻结 moe 路由器(无梯度)
enable_gradient_checkpointing: False
enable_activation_offload: False
trust_remote_code: False
use_remove_padding: False
actor:
strategy: fsdp # 向后兼容
ppo_mini_batch_size: 256
ppo_micro_batch_size: null # 将被弃用,使用 ppo_micro_batch_size_per_gpu
ppo_micro_batch_size_per_gpu: 8
use_dynamic_bsz: False
ppo_max_token_len_per_gpu: 16384 # n * ${data.max_prompt_length} + ${data.max_response_length}
grad_clip: 1.0
clip_ratio: 0.2
entropy_coeff: 0.001
use_kl_loss: False # GRPO 使用 True
use_torch_compile: True # False 禁用 torch 编译
kl_loss_coef: 0.001 # 用于 grpo
kl_loss_type: low_var_kl # 用于 grpo
ppo_epochs: 1
data_loader_seed: null
shuffle: False
ulysses_sequence_parallel_size: 1 # sp 大小
optim:
lr: 1e-6
lr_warmup_steps: -1 # 优先级高于 lr_warmup_steps_ratio,负值表示委托给 lr_warmup_steps_ratio
lr_warmup_steps_ratio: 0. # 总步数将在运行时注入
min_lr_ratio: 0.0 # 仅用于 cosine lr 调度器,默认为 0.0
num_cycles: 0.5 # 仅用于 cosine lr 调度器,默认为 0.5
warmup_style: constant # 从 constant/cosine 中选择
total_training_steps: -1 # 必须由程序覆盖
fsdp_config:
wrap_policy:
# transformer_layer_cls_to_wrap: None
min_num_params: 0
param_offload: False
optimizer_offload: False
fsdp_size: -1
checkpoint:
contents: ['model', 'optimizer', 'extra']
ref:
fsdp_config:
param_offload: False
wrap_policy:
# transformer_layer_cls_to_wrap: None
min_num_params: 0
log_prob_micro_batch_size: null # 将被弃用,使用 log_prob_micro_batch_size_per_gpu
log_prob_micro_batch_size_per_gpu: 16
log_prob_use_dynamic_bsz: ${actor_rollout_ref.actor.use_dynamic_bsz}
log_prob_max_token_len_per_gpu: ${actor_rollout_ref.actor.ppo_max_token_len_per_gpu}
ulysses_sequence_parallel_size: ${actor_rollout_ref.actor.ulysses_sequence_parallel_size} # sp 大小
rollout:
name: vllm
temperature: 1.0
top_k: -1 # hf 回滚为 0,vllm 回滚为 -1
top_p: 1
prompt_length: ${data.max_prompt_length} # 开源不使用
response_length: ${data.max_response_length}
# 用于 vllm 回滚
dtype: bfloat16 # 应与 FSDP 保持一致
gpu_memory_utilization: 0.5
ignore_eos: False
enforce_eager: True
free_cache_engine: True
load_format: dummy_dtensor
tensor_model_parallel_size: 2
max_num_batched_tokens: 8192
max_num_seqs: 1024
log_prob_micro_batch_size: null # 将被弃用,使用 log_prob_micro_batch_size_per_gpu
log_prob_micro_batch_size_per_gpu: 16
log_prob_use_dynamic_bsz: ${actor_rollout_ref.actor.use_dynamic_bsz}
log_prob_max_token_len_per_gpu: ${actor_rollout_ref.actor.ppo_max_token_len_per_gpu}
# 用于 hf 回滚
do_sample: True
engine_kwargs: # 推理引擎参数
vllm:
swap_space: null # null 表示使用引擎默认值(通常为 4 GB),例如设置为 32 表示 32 GB
sglang:
attention_backend: null # null 表示使用引擎默认值,可用选项:flashinfer、triton、flashmla
# 响应数量(即采样次数)
n: 1 # grpo、rloo 使用 > 1
val_kwargs:
# 验证采样参数
top_k: -1 # vllm 回滚为 -1,hf 回滚为 0
top_p: 1.0
temperature: 0
n: 1
do_sample: False # 验证默认使用贪婪
** Common config for actor, rollout and reference model**
actor_rollout_ref.hybrid_engine:是否为混合引擎,目前仅支持混合引擎。actor_rollout_ref.model.path:Huggingface 模型路径。可以是本地路径或 HDFS 路径。对于 HDFS 路径,提供工具将其下载到 DRAM 并将 HDFS 路径转换为本地路径。actor_rollout_ref.model.external_libs:需要导入的额外 Python 包,用于将模型或 tokenizer 注册到 Huggingface 系统。actor_rollout_ref.model.override_config:用于覆盖模型的原始配置,主要用于 dropout。actor_rollout_ref.model.enable_gradient_checkpointing:是否为演员启用梯度检查点。actor_rollout_ref.model.enable_activation_offload:是否为演员启用激活卸载。actor_rollout_ref.model.trust_remote_code:是否启用加载远程代码模型。Actor Model
actor_rollout_ref.actor.strategy:fsdp 或 megatron。本例中使用 fsdp 后端。actor_rollout_ref.actor.ppo_mini_batch_size:一个样本被拆分为多个子批次,批次大小为 ppo_mini_batch_size,用于 PPO 更新。ppo_mini_batch_size 是所有 worker/gpu 的全局数量。actor_rollout_ref.actor.ppo_micro_batch_size:[将被弃用,使用 ppo_micro_batch_size_per_gpu] 类似于梯度累积,每 GPU 的微批次大小,用于一次前向传播,以速度换取 GPU 内存。值表示全局视图。actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu:类似于梯度累积,每 GPU 的微批次大小,用于一次前向传播,以速度换取 GPU 内存。值表示每 GPU 的本地数量。actor_rollout_ref.actor.grad_clip:演员更新的梯度裁剪。actor_rollout_ref.actor.use_kl_loss:是否在演员中使用 KL 损失。启用时,不在奖励函数中应用 KL。actor_rollout_ref.actor.clip_ratio:PPO 裁剪比率。actor_rollout_ref.actor.use_torch_compile:是否在演员中使用 torch 编译。actor_rollout_ref.actor.entropy_coeff:计算 PPO 损失时熵的权重。actor_rollout_ref.actor.ppo_epochs:对一组采样数据进行 PPO 更新的轮次。actor_rollout_ref.actor.data_loader_seed:从 torch 2.6.0 开始,Megatron 后端可能因 pytorch 生成的错误种子导致 cp 进程间数据对齐问题,因此需手动设置种子以避免挂起问题。若 actor_rollout_ref.actor.shuffle 不为空,则必须设置此项。actor_rollout_ref.actor.shuffle:当有多个轮次时是否打乱数据。actor_rollout_ref.actor.optim:演员的优化器参数。actor_rollout_ref.actor.fsdp_config:演员训练的 FSDP 配置。
wrap_policy:FSDP 包装策略。默认使用 Huggingface 的包装策略,即按 DecoderLayer 包装。
*_offload:是否启用参数、梯度和优化器卸载。
actor_rollout_ref.actor.use_kl_loss:是否启用 KL 损失,默认为 False。actor_rollout_ref.actor.kl_loss_coef:KL 损失的系数,默认为 0.001。actor_rollout_ref.actor.kl_loss_type:支持 kl、abs、mse、low_var_kl 和 full。用于计算演员和参考策略之间的 KL 散度。具体选项参见 core_algos.py 中的 kl_penalty()。actor_rollout_ref.actor.checkpoint:演员检查点功能的配置。
contents:检查点保存的内容。默认保存模型、优化器和额外信息。额外信息当前包括 Rng 状态,支持 FSDP 的 lr_scheduler,Megatron 的 opt_param_scheduler 即将推出。默认不存储 hf_model,但提供工具在 scripts/model_merge.py 中将检查点格式转换为 hf 格式。Reference Model
当 actor.use_kl_loss 或/和 algorithm.use_kl_in_reward 为 True 时启用参考模型。
actor_rollout_ref.ref:与演员相同的 FSDP 配置。对于大于 7B 的模型,建议默认启用参考模型的卸载。actor_rollout_ref.ref.log_prob_micro_batch_size:[将被弃用,使用 log_prob_micro_batch_size_per_gpu] 计算 ref_log_prob 时一次前向传播的批次大小。值表示全局数量。actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu:计算 ref_log_prob 时一次前向传播的批次大小。值表示每 GPU 的本地数量。Rollout Model
actor_rollout_ref.rollout.name:hf/vllm/sglang。SamplingParams 中的属性名称。
temperature、top_k、top_p 等:SamplingParams 中的采样参数。actor_rollout_ref.rollout.dtype:回滚模型参数类型,应与 FSDP/Megatron 后端的演员模型参数类型一致。actor_rollout_ref.rollout.gpu_memory_utilization:
mem_fraction_static,用于模型权重和 KV 缓存的静态内存的可用 GPU 内存比例。actor_rollout_ref.rollout.tensor_model_parallel_size:回滚的 TP 大小,仅对 vllm 有效。actor_rollout_ref.rollout.log_prob_micro_batch_size:[将被弃用,使用 log_prob_micro_batch_size_per_gpu] 计算 log_prob 时一次前向传播的批次大小。值表示全局数量。actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu:重新计算 log_prob 的每 GPU 微批次大小(一次前向传播的批次大小)。值表示每 GPU 的本地数量。actor_rollout_ref.rollout.do_sample:训练回滚期间是否采样。若设置为 False,回滚模型将执行贪婪采样。actor_rollout_ref.rollout.val_kwargs:专门用于验证的采样参数。
top_k:Top-k 采样参数。vLLM 回滚默认为 -1,HF 回滚为 0。top_p:Top-p 采样参数,默认为 1.0(禁用)。temperature:采样温度,默认为 0(确定性贪婪)。n:验证期间生成的响应数量,默认为 1。do_sample:验证期间是否使用采样,默认为 False 以获得确定性输出。若设置为 True,回滚将使用 actor_rollout_ref.rollout.val_kwargs 参数(top_k、top_p、temperature)控制采样行为。actor_rollout_ref.rollout.engine_kwargs.vllm:额外的 vllm 引擎参数。
swap_space:推理引擎使用的交换空间(GB)。
null:表示不设置,使用引擎默认值(通常为 4 GB)。32 表示 32 GB。actor_rollout_ref.rollout.engine_kwargs.sglang:额外的 sglang 引擎参数。
attention_backend:推理引擎使用的注意力后端。
null:表示不设置,使用引擎默认值(通常为 fa3)。flashinfer:使用 flashinfer 注意力后端。triton:使用 triton 注意力后端。flashmla:使用 flashmla 注意力后端。actor_rollout_ref.rollout.ignore_eos:是否忽略 EOS 标记并在生成 EOS 标记后继续生成标记。actor_rollout_ref.rollout.free_cache_engine:在回滚生成阶段后卸载 KVCache,默认为 True。启用时,需禁用 CUDAGraph 的使用(将 enforce_eager 设置为 True)。actor_rollout_ref.rollout.enforce_eager:是否在 vLLM 生成中使用 CUDAGraph,默认为 True 以禁用 CUDAGraph。actor_rollout_ref.rollout.load_format:用于加载演员模型权重到回滚模型的权重加载器。
auto:使用 Megatron 权重加载器。megatron:使用 Megatron 权重加载器。与 Megatron 后端部署。输入模型的 state_dict() 已沿 TP 维度分区并沿 PP 维度聚集。此权重加载器要求回滚模型和演员模型的参数形状和名称相同。dtensor:使用 Huggingface 权重加载器时的默认解决方案。与 FSDP 后端部署,state_dict_type 为 StateDictType.SHARDED_STATE_DICT。推荐使用此权重加载器。hf:使用 Huggingface 权重加载器。与 FSDP 后端部署,state_dict_type 为 StateDictType.FULL_STATE_DICT。此解决方案无需为 vLLM 中实现的每个模型重写权重加载器,但会导致更高的峰值内存使用量。dummy_hf、dummy_megatron、dummy_dtensor:随机初始化。注意:在此配置字段中,用户仅需从 dummy_megatron、dummy_dtensor、dummy_hf 中选择用于回滚初始化,我们的混合引擎将在演员/回滚权重同步期间选择相应的权重加载器(即 megatron、dtensor、hf)。
评判模型的大多数参数与演员模型类似。
reward_model:
enable: False
model:
input_tokenizer: ${actor_rollout_ref.model.path} # 若聊天模板相同,可设置为 null
path: ~/models/Anomy-RM-v0.1
external_lib: ${actor_rollout_ref.model.external_lib}
trust_remote_code: False
fsdp_config:
min_num_params: 0
param_offload: False
micro_batch_size_per_gpu: 16
max_length: null
reward_manager: naive
reward_model.enable:是否启用奖励模型。若为 False,仅使用用户定义的奖励函数计算奖励。在 GSM8K 和数学示例中,我们禁用奖励模型。对于使用 full_hh_rlhf 的 RLHF 对齐示例,我们利用奖励模型评估响应。若为 False,以下参数无效。reward_model.model
input_tokenizer:输入 tokenizer。若奖励模型的聊天模板与策略不一致,需先解码为纯文本,然后应用奖励模型的聊天模板,再用奖励模型评分。若聊天模板一致,可设置为 null。path:奖励模型的 HDFS 路径或本地路径。注意,奖励模型仅支持 AutoModelForSequenceClassification。其他模型类型需定义自己的 RewardModelWorker 并从代码中传递。trust_remote_code:是否启用加载远程代码模型,默认为 False。reward_model.reward_manager:奖励管理器。定义基于规则的奖励计算机制和处理不同奖励来源的方式。默认为 naive。若所有验证函数都支持多进程安全,可将奖励管理器设置为 prime 以进行并行验证。custom_reward_function:
path: null
name: compute_score
custom_reward_function.path:包含自定义奖励函数的文件路径。若未指定,使用预实现的奖励函数。custom_reward_function.name(可选):指定文件中奖励函数的名称,默认为 ‘compute_score’。algorithm:
gamma: 1.0
lam: 1.0
adv_estimator: gae
use_kl_in_reward: False
kl_penalty: kl # 如何估计 KL 散度
kl_ctrl:
type: fixed
kl_coef: 0.005
horizon: 10000
target_kl: 0.1
gamma:折扣因子。lam:GAE 估计器中偏差与方差的权衡。adv_estimator:支持 gae、grpo、reinforce_plus_plus、reinforce_plus_plus_baseline、rloo。use_kl_in_reward:是否启用奖励中的 KL 惩罚,默认为 False。kl_penalty:支持 kl、abs、mse、low_var_kl 和 full。用于计算演员和参考策略之间的 KL 散度。具体选项参见 core_algos.py 中的 kl_penalty()。kl_ctrl:奖励中 KL 惩罚控制器的配置。
kl_coef:奖励中 KL 惩罚的(初始)系数,默认为 0.001。type:‘fixed’ 表示 FixedKLController,‘adaptive’ 表示 AdaptiveKLController。horizon 和 target_kl:详见 AdaptiveKLController 的源代码。trainer:
total_epochs: 30
project_name: verl_examples
experiment_name: gsm8k
logger: ['console', 'wandb']
log_val_generations: 0
nnodes: 1
n_gpus_per_node: 8
save_freq: -1
val_before_train: True
test_freq: 2
critic_warmup: 0
default_hdfs_dir: ~/experiments/gsm8k/ppo/${trainer.experiment_name} # hdfs 检查点路径
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name} # 本地检查点路径
resume_mode: auto # 或 disable 或 resume_path(若设置 resume_from_path)
resume_from_path: null
remove_previous_ckpt_in_save: False
del_local_ckpt_after_load: False
ray_wait_register_center_timeout: 300
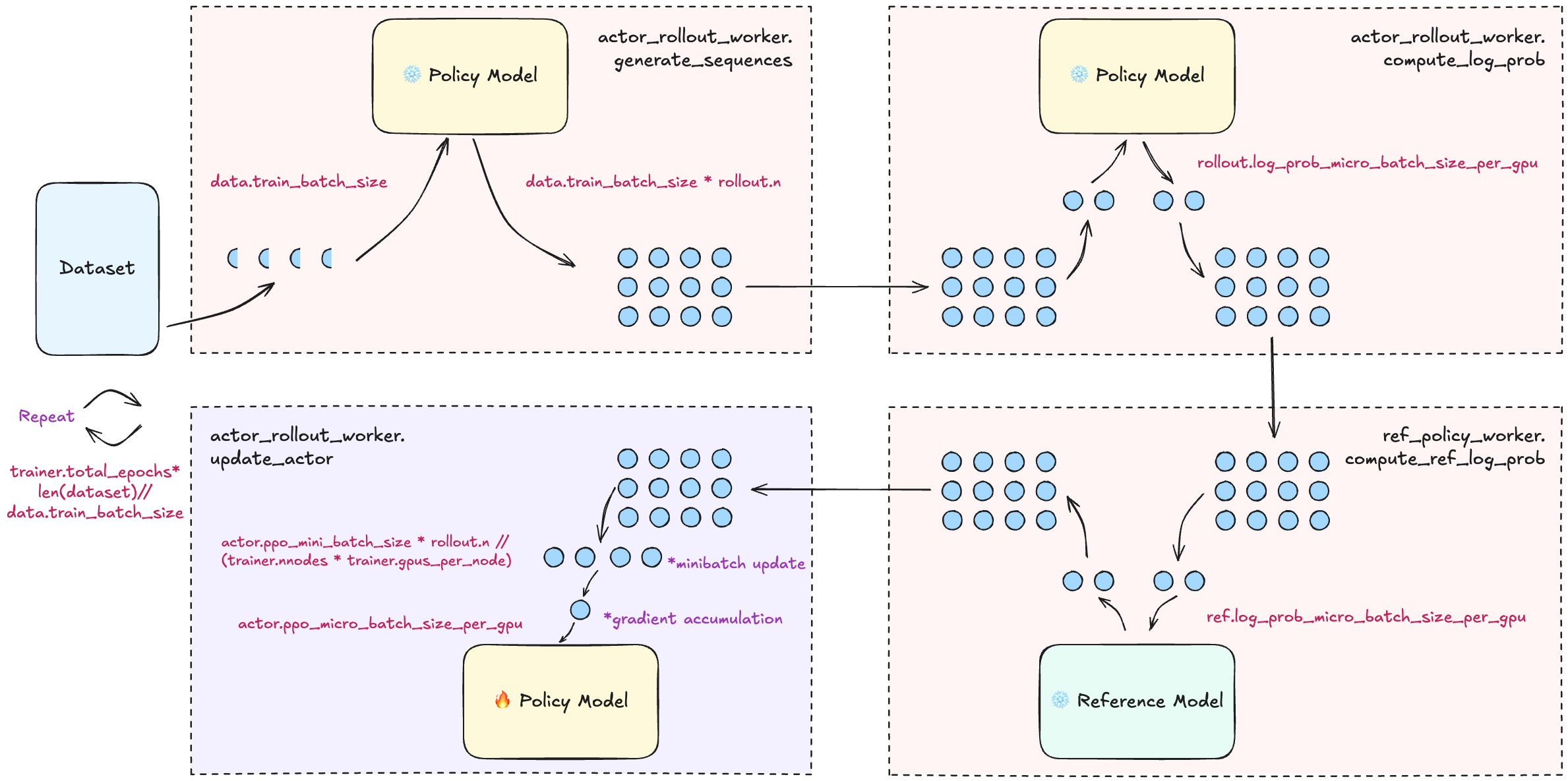
trainer.total_epochs:训练中的轮次。trainer.project_name:用于 wandb、swanlab、mlflow。trainer.experiment_name:用于 wandb、swanlab、mlflow。trainer.logger:支持 console、wandb、swanlab、mlflow、tensorboard。trainer.log_val_generations:验证期间记录的生成数量(默认为 0)。trainer.nnodes:训练中使用的节点数。trainer.n_gpus_per_node:每节点的 GPU 数量。trainer.save_freq:保存演员和评判模型检查点的频率(按迭代)。trainer.val_before_train:是否在训练前运行验证。trainer.test_freq:验证频率(按迭代)。trainer.critic_warmup:在实际策略学习之前训练评判模型的迭代次数。trainer.resume_mode:恢复训练的模式。支持 disable、auto 和 resume_path。默认为 auto,程序将自动从 default_hdfs_dir 中的最新检查点恢复。若设置为 resume_path,程序将从 resume_from_path 指定的路径恢复。trainer.resume_from_path:恢复训练的路径,仅在 resume_mode 设置为 resume_path 时有效。trainer.remove_previous_ckpt_in_save:是否删除保存目录中的先前检查点,默认为 False。trainer.del_local_ckpt_after_load:加载后是否删除本地检查点,默认为 False。trainer.ray_wait_register_center_timeout:等待 ray 注册中心就绪的超时时间,默认为 300 秒。此图说明了配置如何影响训练:
https://excalidraw.com/#json=pfhkRmiLm1jnnRli9VFhb,Ut4E8peALlgAUpr7E5pPCA
data:
path: /tmp/math_Qwen2-7B-Instruct.parquet
prompt_key: prompt
response_key: responses
data_source_key: data_source
reward_model_key: reward_model
data.path:数据集文件的路径(Parquet 格式)。data.prompt_key:数据集中存储提示的字段,默认为 ‘prompt’。data.response_key:存储生成响应的键,应为字符串列表,默认为 ‘responses’。data.data_source_key:用于为不同数据源分开计算指标,确保每个数据源的指标独立计算。data.reward_model_key:存储参考答案的键,通常作为任务的真实答案或测试用例。custom_reward_function:
path: null
name: compute_score
custom_reward_function.path:包含自定义奖励函数的文件路径。若未指定,使用预实现的奖励函数。custom_reward_function.name(可选):指定文件中奖励函数的名称,默认为 ‘compute_score’。optim:
lr: 1e-5
weight_decay: 0.01
warmup_steps_ratio: 0.1
clip_grad: 1.0
lr_scheduler: cosine
optim.lr:优化器的学习率。optim.weight_decay:优化器的权重衰减。optim.warmup_steps_ratio:预热步数占总训练步数的比例。optim.clip_grad:梯度裁剪值。optim.lr_scheduler:学习率调度器类型。选项:
cosine:带预热的余弦学习率调度器(默认)。wsd:预热-稳定-衰减调度器,在预热和衰减阶段之间提供稳定学习率阶段。Source:PPO Example Architecture — verl documentation
让我们从近端策略优化(Proximal Policy Optimization, PPO)算法开始,这是大语言模型(LLM)后训练中最广泛使用的算法。
PPO算法示例的主要入口点是:main_ppo.py。在本教程中,我们将详细介绍 main_ppo.py 中的代码架构。
用户需要预处理并将数据集存储为parquet文件。我们实现了RLHFDataset来加载和分词parquet文件。
对于RLHFDataset(默认),至少需要1个字段:
prompt:包含字符串提示我们已在data_preprocess目录中提供了一些处理数据集为parquet文件的示例。目前,我们支持GSM8k、MATH、Hellasage、Full_hh_rlhf数据集的预处理。更多信息请参见后训练数据准备。
在这个主要入口点中,用户只需根据PPO训练中使用的数据集(或应用)定义自己的奖励函数。
例如,我们已经在_select_rm_score_fn中为GSM8k和MATH数据集提供了奖励函数。在RewardManager中,我们将根据数据源选择相应的奖励函数来计算奖励分数。对于一些RLHF数据集(例如full_hh_rlhf),奖励模型直接用于评估响应,不需要额外的奖励函数。在这种情况下,RewardManager将直接返回由奖励模型计算的rm_score。
有关详细实现,请参见奖励函数。
if config.actor_rollout_ref.actor.strategy == 'fsdp': # 对于FSDP后端
assert config.actor_rollout_ref.actor.strategy == config.critic.strategy
from verl.workers.fsdp_workers import ActorRolloutRefWorker, CriticWorker
from verl.single_controller.ray import RayWorkerGroup
ray_worker_group_cls = RayWorkerGroup
elif config.actor_rollout_ref.actor.strategy == 'megatron': # 对于Megatron后端
assert config.actor_rollout_ref.actor.strategy == config.critic.strategy
from verl.workers.megatron_workers import ActorRolloutRefWorker, CriticWorker
from verl.single_controller.ray.megatron import NVMegatronRayWorkerGroup
ray_worker_group_cls = NVMegatronRayWorkerGroup # Megatron-LM的Ray工作类
else:
raise NotImplementedError
from verl.trainer.ppo.ray_trainer import ResourcePoolManager, Role
role_worker_mapping = {
Role.ActorRollout: ActorRolloutRefWorker,
Role.Critic: CriticWorker,
Role.RefPolicy: ActorRolloutRefWorker
}
global_pool_id = 'global_pool'
resource_pool_spec = {
global_pool_id: [config.trainer.n_gpus_per_node] * config.trainer.nnodes,
}
mapping = {
Role.ActorRollout: global_pool_id,
Role.Critic: global_pool_id,
Role.RefPolicy: global_pool_id,
}
角色表示同一进程中的一组工作进程。我们已在ray_trainer.py中预定义了几个角色。
class Role(Enum):
"""
要动态创建更多角色,可以继承Role并添加新成员
"""
Actor = 0 # 该工作进程仅包含Actor
Rollout = 1 # 该工作进程仅包含Rollout
ActorRollout = 2 # 该工作进程同时包含Actor和Rollout,是一个HybridEngine
Critic = 3 # 该工作进程仅包含Critic
RefPolicy = 4 # 该工作进程仅包含参考策略
RewardModel = 5 # 该工作进程仅包含奖励模型
ActorRolloutRef = 6 # 该工作进程同时包含Actor、Rollout和参考策略
我们已预实现ActorRolloutRefWorker。通过不同的配置,它可以是独立的Actor、独立的Rollout、ActorRollout混合引擎,或ActorRolloutRef混合引擎。
我们还为Actor、Rollout、Critic、Reward Model和Reference Model在PyTorch FSDP和Megatron-LM两种后端上预实现了工作类。更多信息请参见FSDP工作类和Megatron-LM工作类。
资源池是全局GPU资源的划分,resource_pool_spec是一个字典,从ID映射到GPU数量。
global_pool_id,然后将所有角色放置在这个资源池中,使用后训练任务中的所有GPU。这称为_协同放置_,即所有模型共享同一组GPU。有关资源池和放置的高级用法,请参见相关文档。
# 我们应在此采用多源奖励函数
# - 对于基于规则的奖励模型,我们直接调用奖励分数
# - 对于基于模型的奖励模型,我们调用模型
# - 对于与代码相关的提示,如果有测试用例,我们发送到沙箱
# - 最后,我们将所有奖励组合在一起
# - 奖励类型取决于数据的标签
if config.reward_model.enable:
from verl.workers.fsdp_workers import RewardModelWorker
role_worker_mapping[Role.RewardModel] = RewardModelWorker
mapping[Role.RewardModel] = global_pool_id
reward_fn = RewardManager(tokenizer=tokenizer, num_examine=0)
# 注意,我们始终使用基于函数的奖励模型进行验证
val_reward_fn = RewardManager(tokenizer=tokenizer, num_examine=1)
resource_pool_manager = ResourcePoolManager(resource_pool_spec=resource_pool_spec, mapping=mapping)
由于并非所有任务都使用基于模型的奖励模型,用户需要在此定义是基于模型的奖励模型还是基于函数的奖励模型。
如果是基于模型的奖励模型,直接在资源映射中添加RewardModel角色,并将其添加到资源池映射中。
RewardModelWorker仅支持huggingface AutoModelForSequenceClassification结构的模型。如果不是这种模型,用户需要在FSDP工作类和Megatron-LM工作类中定义自己的RewardModelWorker。如果是基于函数的奖励模型,用户需要为每个数据集分类奖励函数。
def _select_rm_score_fn(data_source):
if data_source == 'openai/gsm8k':
return gsm8k.compute_score
elif data_source == 'lighteval/MATH':
return math.compute_score
else:
raise NotImplementedError
有关奖励函数的实现,请参见目录。
trainer = RayPPOTrainer(config=config,
tokenizer=tokenizer,
role_worker_mapping=role_worker_mapping,
resource_pool_manager=resource_pool_manager,
ray_worker_group_cls=ray_worker_group_cls,
reward_fn=reward_fn,
val_reward_fn=val_reward_fn)
trainer.init_workers()
trainer.fit()
我们首先使用用户配置、分词器以及上述工作类映射、资源池、工作组和奖励函数初始化RayPPOTrainer。
首先调用trainer.init_workers()在分配的GPU(资源池中)上初始化模型。
实际的PPO训练将在trainer.fit()中执行。
verl可以通过重用Ray模型工作类、资源池和奖励函数轻松扩展到其他强化学习算法。更多信息请参见扩展。
RayPPOTrainer的细节在Ray训练器中讨论。
Source:Multi-Modal Example Architecture — verl documentation
现在,verl 已支持多模态训练。您可以使用 fsdp 和 vllm/sglang 来启动多模态 RL 任务。Megatron 支持也即将推出。
按照以下步骤快速启动多模态 RL 任务。
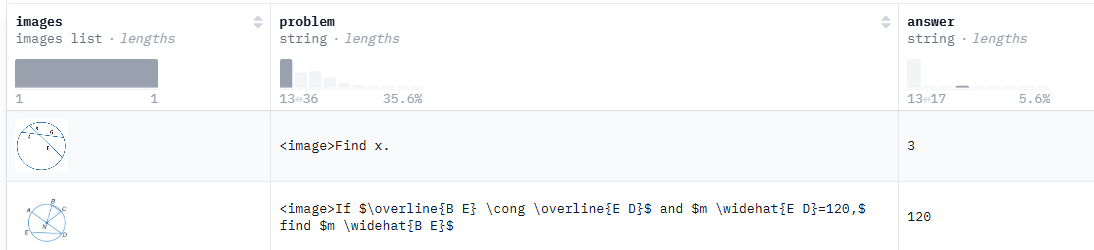
这个数据集是一些几何题目:
# 数据将保存在 $HOME/data/geo3k 文件夹中
python examples/data_preprocess/geo3k.py
这里面对于数据的构造部分如下:
def make_map_fn(split):
def process_fn(example, idx):
problem = example.pop("problem")
prompt = problem + " " + instruction_following
answer = example.pop("answer")
images = example.pop("images")
data = {
"data_source": data_source,
"prompt": [
{
"role": "user",
"content": prompt,
}
],
"images": images,
"ability": "math",
"reward_model": {"style": "rule", "ground_truth": answer},
"extra_info": {
"split": split,
"index": idx,
"answer": answer,
"question": problem,
},
}
return data
return process_fn
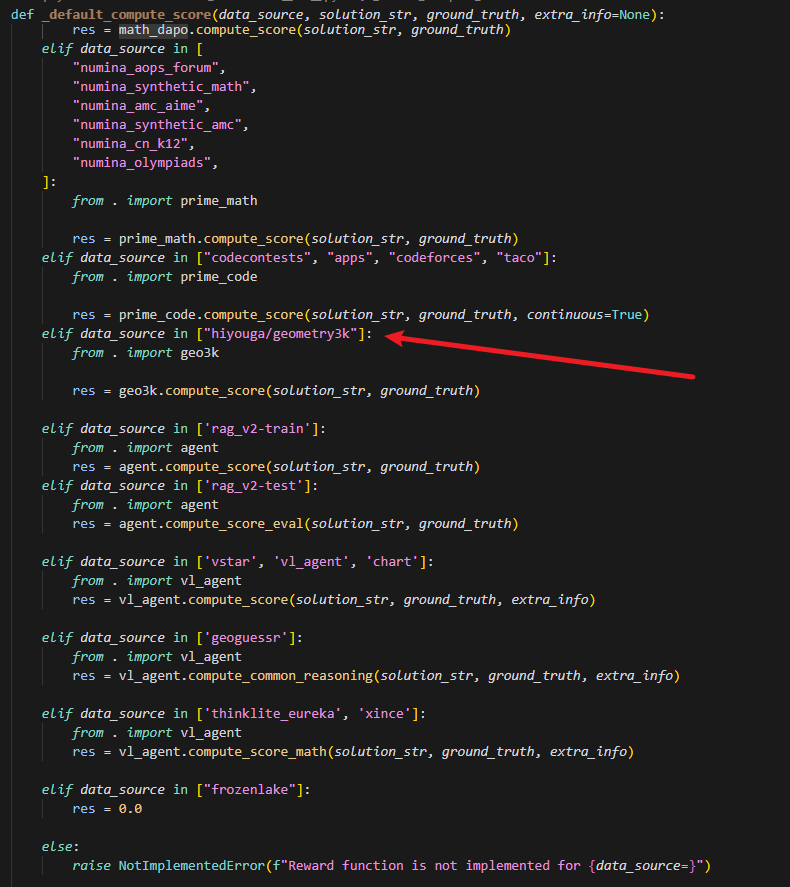
这里的 data_source 会决定用哪个函数计算 reward 得分
见 verl/utils/reward_score/__init__.py 文件里面:
# 从 Hugging Face 下载模型
python3 -c "import transformers; transformers.pipeline(model='Qwen/Qwen2.5-VL-7B-Instruct')"
# 运行任务
bash examples/grpo_trainer/run_qwen2_5_vl-7b.sh
我把脚本改成了这样:
set -x
ENGINE=${1:-vllm}
# If you are using vllm<=0.6.3, you might need to set the following environment variable to avoid bugs:
# export VLLM_ATTENTION_BACKEND=XFORMERS
PROJECT_NAME=verl_grpo_example_geo3k
EXPERIMENT_NAME=qwen2_5_vl_3b_function_rm
GPU_NUM=4
DATA_DIR=/local_nvme/xxx/datasets/verl_data/geo3k
MODEL_DIR=/model/huggingface/hub/Qwen2.5-VL-3B-Instruct
EPOCHS=15
python3 -m verl.trainer.main_ppo \
algorithm.adv_estimator=grpo \
data.train_files=${DATA_DIR}/train.parquet \
data.val_files=${DATA_DIR}/test.parquet \
data.train_batch_size=512 \
data.max_prompt_length=1024 \
data.max_response_length=2048 \
data.filter_overlong_prompts=True \
data.truncation='error' \
data.image_key=images \
actor_rollout_ref.model.path=${MODEL_DIR} \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.model.use_remove_padding=True \
actor_rollout_ref.actor.ppo_mini_batch_size=128 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=10 \
actor_rollout_ref.actor.use_kl_loss=True \
actor_rollout_ref.actor.kl_loss_coef=0.01 \
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
actor_rollout_ref.actor.entropy_coeff=0 \
actor_rollout_ref.model.enable_gradient_checkpointing=True \
actor_rollout_ref.actor.fsdp_config.param_offload=False \
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=20 \
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
actor_rollout_ref.rollout.name=$ENGINE \
actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \
actor_rollout_ref.rollout.enable_chunked_prefill=False \
actor_rollout_ref.rollout.enforce_eager=False \
actor_rollout_ref.rollout.free_cache_engine=False \
actor_rollout_ref.rollout.n=5 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=20 \
actor_rollout_ref.ref.fsdp_config.param_offload=True \
algorithm.use_kl_in_reward=False \
trainer.critic_warmup=0 \
trainer.logger=['console','wandb'] \
trainer.project_name=${PROJECT_NAME} \
trainer.experiment_name=${EXPERIMENT_NAME} \
trainer.n_gpus_per_node=${GPU_NUM} \
trainer.nnodes=1 \
trainer.save_freq=-1 \
trainer.test_freq=5 \
trainer.total_epochs=${EPOCHS} $@