来源链接:On-Policy Distillation - Thinking Machines Lab
大语言模型之所以能在特定领域达到专家级表现,是多种能力叠加的结果:输入感知、知识检索、方案选择与可靠执行。这需要一套完整的训练流程,大致可分为三个阶段:
- 预训练:学习语言使用、基础推理、世界知识等通用能力。
- 中期训练:注入领域知识,如代码、医学数据库、企业内部文档等。
- 后期训练:引导目标行为,如遵循指令、数学推理、对话等。
经过充分训练的小模型,在其专精领域往往优于更大的通用模型。使用小模型有诸多好处:可本地部署以保障隐私与安全、更容易持续训练与更新、并降低推理成本。要发挥这些优势,需要为后期训练选择合适的方法。
对“学生”模型进行后期训练的方法主要分为两类:
- 在线策略训练(On-policy):从学生模型自身采样轨迹,并赋予相应奖励。
- 离线策略训练(Off-policy):依赖外部来源的目标输出,让学生模型学习模仿。
例如,我们希望训练一个轻量模型来解决数学题:

我们可以通过强化学习进行在线策略训练,对学生模型的每一条生成轨迹评分,判断其是否正确解题。评分可由人类或能稳定输出正确答案的“教师”模型完成。

在线策略训练的优势在于:通过对自身生成样本进行训练,学生模型能更直接地学会避免错误。但强化学习有一个明显缺点:反馈非常稀疏,每个训练轮次只传递固定比特数的信息,与生成的 Token 数量无关。
在上面的例子中,学生模型只会知道“21”是错误答案,并避免生成这条轨迹,但不知道具体错在哪里——是运算顺序错了,还是算术本身算错了。这种反馈稀疏性让强化学习在很多场景下效率很低。
离线策略训练通常使用监督微调(SFT):在精心标注的任务专属数据集上训练。这些标注数据可以来自在该任务上表现优异的教师模型。
我们可以使用一种叫蒸馏的机制:训练学生模型去拟合教师模型的输出分布。我们用教师的完整轨迹进行训练:包括中间思考步骤在内的全部生成 Token 序列。
我们可以在每一步使用教师完整的下一 Token 分布(常称为“Logit 蒸馏”),或只采样给定序列。实际中,采样序列能无偏估计教师分布,并达到相同优化目标。
学生模型会朝着序列中每个 Token 方向更新,更新幅度与自身生成该 Token 的概率负相关,下图中颜色越深表示更新幅度越大:

从大模型教师蒸馏已被证明能有效训练小模型,使其具备:
- 遵循指令能力
- 数学与科学推理能力
- 从医学文本中提取临床信息能力
- 多轮对话能力
用于这些任务的蒸馏数据集通常会开源并公开发布。
离线策略训练的缺点是:学生模型在教师常遇到的场景中学习,而不是在自己实际会遇到的场景中学习。这会导致误差累积:如果学生模型在早期犯了一个教师从未犯过的错误,就会越来越偏离训练时见过的状态。在长序列生成任务中,这个问题尤为严重。要避免这种偏离,学生模型必须学会从自己的错误中恢复。
离线蒸馏的另一个问题是:学生可能学会模仿教师的风格与自信,却不一定学到事实准确性。
打个比方:学习下棋时,在线策略强化学习就像没人指导自己对弈,输赢只在对局结束后给出一次反馈,无法告诉你哪一步最关键。
离线策略蒸馏则像看大师下棋——你能看到极强的棋路,但这些局面新手自己几乎遇不到。
我们希望结合:
- 强化学习的在线策略相关性
- 蒸馏的稠密奖励信号
放到下棋里,就是有一位教练对你自己走的每一步从“失误”到“妙手”分级打分。
放到大模型后期训练里,这就是在线策略蒸馏。
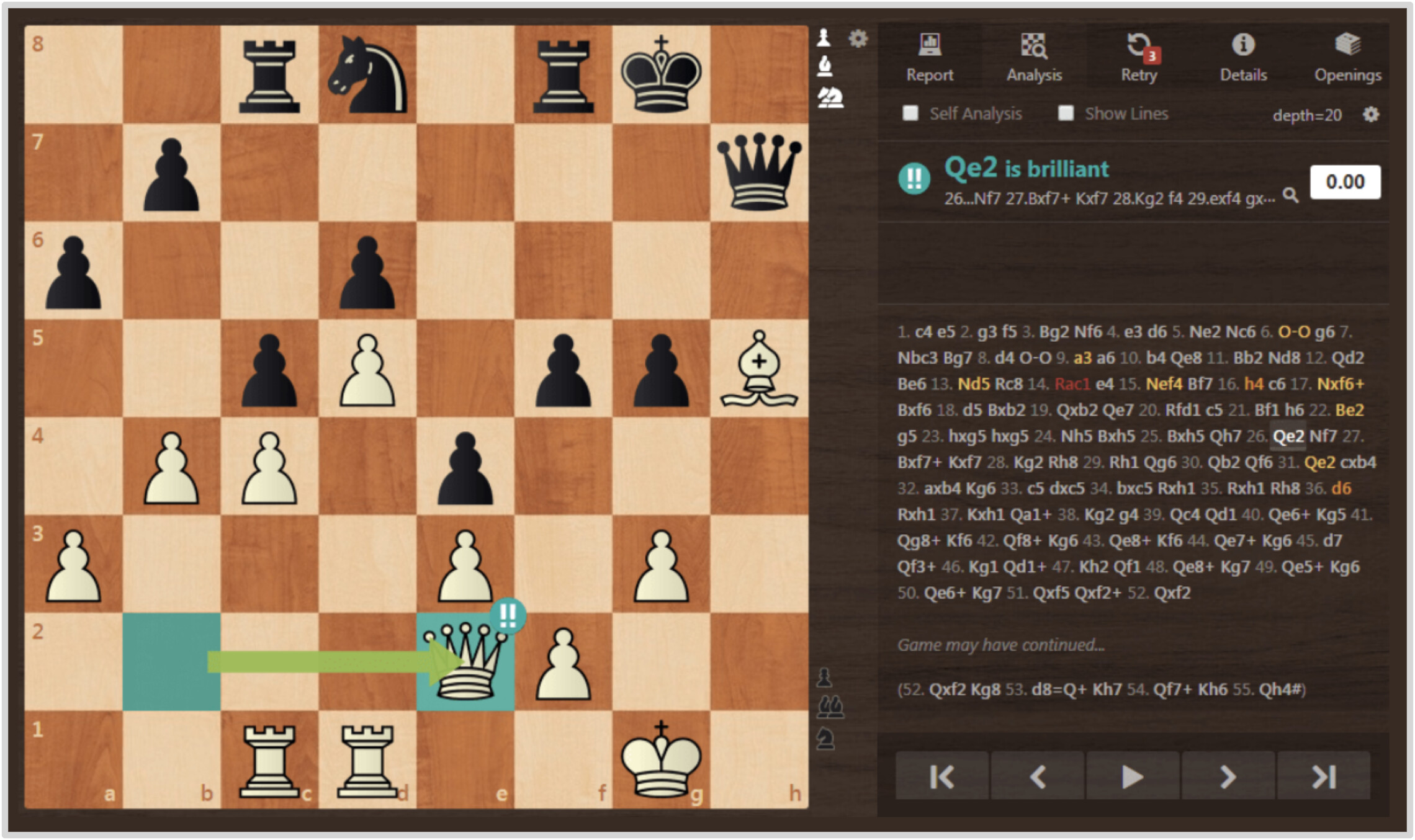
截图来自 chess.com。每一步都会被分析引擎用颜色评级:失误(红)、错误(橙)、不准确(黄)、妙手(蓝)。
在线策略蒸馏——兼得二者之长
在线策略蒸馏的核心思想:
从学生模型采样轨迹,用高性能教师模型对每条轨迹的每个 Token 逐一评分。
回到数学题的例子,在线策略蒸馏会对解题的每一步打分:惩罚导致错误的步骤,强化正确执行的步骤。

本文探索在线策略蒸馏在以下任务中的应用:
- 数学推理模型训练
- 融合领域知识与指令遵循的助手模型训练
我们在已完成预训练与中期训练的模型上应用在线策略蒸馏,发现它是一种低成本且强大的后期训练方案,同时具备在线策略训练的优势与稠密奖励信号的高效性。
| 方法 | 采样方式 | 奖励信号 |
|---|---|---|
| 监督微调 | 离线策略 | 稠密 |
| 强化学习 | 在线策略 | 稀疏 |
| 在线策略蒸馏 | 在线策略 | 稠密 |
我们的工作受以下研究启发:
- DAGGER:一种迭代式 SFT 算法,包含教师对学生访问状态的评估
- 过程奖励模型(PRM):对学生模型思维链的每一步打分
- 此前一系列在线策略蒸馏工作(Agarwal 等、Gu 等、Qwen3 团队)
借助 Tinker 训练 API,我们复现了 Qwen3 的结果:用在线策略蒸馏以远低于强化学习的成本,在推理基准上达到同等性能。
实现方法
你可以在 Tinker cookbook 中查看实现的每一步细节。
损失函数:反向 KL 散度
在线策略蒸馏可使用多种损失函数对学生轨迹评分。为简单起见,我们选用逐 Token 反向 KL:
在相同历史轨迹下,学生分布 \pi_\theta 与教师分布 \pi_{\text{teacher}} 之间的散度:
我们的奖励函数最小化反向 KL,促使学生在自己遇到的每一个状态下都逼近教师行为。当学生与教师行为完全一致时,反向 KL 为 0。
为简化,我们使用折扣因子 0:在任意时刻,学生只优化当前下一 Token,不考虑未来 Token。
反向 KL 与强化学习天然契合,后者通常优化由奖励模型诱导的序列级反向 KL。
但与实际中大多数奖励模型不同,反向 KL 是**“不可作弊”**的:低 KL 始终对应教师视角下高概率的期望行为。
反向 KL 的另外两个有用性质:
- 模式寻求(mode seeking):学习教师的某一种具体行为,而不是在多个次优选项间分散分布
- 减轻曝光偏差(exposure bias)
该方法能显著节省计算:
- 不需要等轨迹完整采样即可计算奖励
- 可使用更短或部分轨迹训练
- 查询教师的对数概率只需要大模型单次前向传播
- 轨迹由更小、更便宜的学生模型生成
我们也不需要单独的奖励模型或标注模型。将基于蒸馏的逐 Token 奖励与序列级环境奖励结合可能存在优势,这是未来值得研究的方向。
图示说明
下面是教师对学生错误轨迹打分的真实案例,来自 SimpleBench。
问题的关键在于物理常识:冰块在煎锅里会融化,所以正确答案是“B. 0”。
学生模型 Qwen3-4B-Instruct-2507 错误地把它当成纯数学题,忽略物理上下文。

教师模型对示例轨迹打分。深红色 Token 对应更高的反向 KL。
颜色越深,表示该 Token 受到教师模型(Qwen3-235B-A22B-Instruct-2507)的惩罚越高。可以看到,模型会惩罚那些引导推理走向错误的起始短语,直观对应指导推理的关键“分叉 Token”。
最终答案虽然错误,但并未被惩罚——因为基于前面整个序列,它是完全可预测的。
伪代码
我们在 Tinker 的强化学习脚本之上实现在线策略蒸馏,该脚本已实现采样、奖励计算与策略梯度式训练。
实际上,在使用 KL 正则的强化学习实现上,只需要改一行代码:替换正则模型即可。
- 初始化教师客户端:Tinker API 可轻松为不同模型创建客户端,无需关心引擎利用率。
- 采样轨迹:像强化学习一样从学生模型采样轨迹,并计算学生对数概率。
- 计算奖励:用
compute_logprobs查询教师在学生采样轨迹上的对数概率,计算反向 KL。 - 用强化学习训练:将逐 Token 优势函数设为负反向 KL,调用重要性采样损失函数更新学生模型。
# 初始化教师客户端
teacher_client = service_client.create_sampling_client(
base_model=teacher_config.base_model,
model_path=teacher_config.load_checkpoint_path,
)
# 采样轨迹
trajectories = do_group_rollout(student_client, env_group_builder)
sampled_logprobs = trajectories.loss_fn_inputs["logprobs"]
# 计算奖励
teacher_logprobs = teacher_client.compute_logprobs(trajectories)
reverse_kl = sampled_logprobs - teacher_logprobs
trajectories["advantages"] = -reverse_kl
# 训练
training_client.forward_backward(trajectories, loss_fn="importance_sampling")
在下面实验中,我们通常对已完成特定领域中期训练的模型使用在线策略蒸馏。这会提高学生生成教师分布内 Token 的概率,但通常远不足以复现教师性能。
我们用在线策略蒸馏做后期训练,并与其他专家模型训练方法对比。
面向推理的蒸馏
我们以 Qwen3-32B 为教师,在 Qwen3-8B-Base 上训练数学推理能力。
教师与学生均为 Tinker 支持模型,你可以用 Tinker cookbook 复现实验。
离线策略蒸馏
所有实验均以离线策略蒸馏形式的中期训练为起点:在教师生成样本数据集上做监督微调。
数学推理所用数据集为 OpenThoughts-3:由 QwQ-32B 生成的推理提示与响应集合。
用 40 万条提示全量微调学生模型,在 AIME’24 数学基准上达到 60% 准确率。
也可以用 LoRA 训练,但在大规模数据上落后于全量微调。
在所有情况下,性能都呈对数线性提升:初期收益廉价,后期昂贵。

我们把 40 万条提示微调后的模型作为检查点,尝试不同后期训练方法提升性能。
对比将 AIME’24 分数从 60% 提升到 70% 所需的成本。
标准方法是继续用更多提示做离线蒸馏。根据对数线性趋势外推,模型大约需要 200 万条提示才能达到 70%。这一外推依赖缩放定律保持有效,并非小事,但已有大规模离线蒸馏将 8B 模型性能推到 70% 以上的案例。
强化学习
Qwen3 技术报告显示:在类似 SFT 初始化基础上,用 17920 卡时的强化学习,将基准性能提升到 67.6%。
很难直接与蒸馏成本对比,但在合理假设下,这与训练 200 万条离线蒸馏提示的成本相近。
| 方法 | AIME’24 | GPQA-Diamond | 显卡时长 |
|---|---|---|---|
| 离线策略蒸馏 | 55.0% | 55.6% | 未报告 |
| + 强化学习 | 67.6% | 61.3% | 17920 |
| + 在线策略蒸馏 | 74.4% | 63.3% | 1800 |
Qwen3 团队还报告:用在线策略蒸馏以十分之一的强化学习成本,在 AIME’24 上达到 74.4%。这也是本文工作的灵感来源。
在线策略蒸馏
从 40 万条 SFT 检查点开始,在线策略蒸馏大约用 150 步就将 AIME’24 提升到 70%(对应约 7.7 万条提示)。

在线策略蒸馏的计算效率显著高于 SFT,尤其对 LoRA 模型。
秩为 32 时,LoRA 在 SFT 后比全量微调低 13%,但在在线蒸馏后只低 6%。
不同方法的计算成本对比比较复杂,我们用 FLOPs 衡量:
| 方法 | AIME’24 | 教师 FLOPs | 学生 FLOPs | 计算效率倍数 |
|---|---|---|---|---|
| 初始化:SFT-400K | 60% | 8.5 × 10²⁰ | 3.8 × 10²⁰ | – |
| SFT-2M(外推) | ~70% | 3.4 × 10²¹ | 1.5 × 10²¹ | 1× |
| 强化学习 | 68% | - | - | ≈1× |
| 在线策略蒸馏 | 70% | 8.4 × 10¹⁹ | 8.2 × 10¹⁹ | 9–30× |
在已有离线蒸馏数据集时,成本降低 9 倍;
若包含教师生成离线数据的全部成本,总成本降低约 30 倍;
实际显卡时长收益接近 18 倍。
面向个性化的蒸馏
除了让小模型在通用任务上达到高性能,蒸馏的另一个用途是个性化:
- 保持特定对话语气与输出格式
- 工具使用、成本预算等能力
我们通常希望在学习新知识的同时训练这类行为。
同时训练两者通常很困难,轻量微调往往不够,需要更大规模的中期训练。在新知识之上学习后期训练行为需要复杂的技术栈,通常包含私有数据与奖励模型,只有头部实验室能轻松做到,其他从业者难以复现或成本过高。
本节展示:在线策略蒸馏可有效用于后期训练专属行为,也适用于持续学习或测试时训练:在部署时更新模型,且不退化基础性能。
我们以在企业内部文档上做过中期训练的模型为例。
训练内部助手
自定义模型的一个常见目标是充当助手:
- 具备领域知识(企业文档)
- 表现出良好的后期训练行为(指令遵循)
我们分别用内部知识检索评测(Internal QA)与 IF-eval 衡量。
新知识训练会破坏已学习行为
我们从已用 RL 做过后期训练(指令遵循、推理)的 Qwen3-8B 开始。
已有研究表明,这类强化学习只训练原模型的小型子网络,因此在后续大量数据训练时比较脆弱。
为减轻灾难性遗忘,中期训练的常见做法是混入原始预训练分布的“背景数据”。
由于我们没有 Qwen3 预训练分布,我们采用更强、更贵的基线:
用 Qwen3-8B 重新采样 Tulu3 提示(广泛的对话与指令遵循数据集)作为对话背景数据。
这种由 Qwen3-8B 采样的“在线策略”背景数据作为前向 KL 正则项,在中期训练中强化模型原始行为。
我们发现用 Qwen3-8B 采样比 Qwen3-32B 更能保留对话能力,凸显数据源的敏感性。
然后我们在内部文档与对话数据的不同混合比例上微调 Qwen3-8B。
文档数据比例提升会直接改善知识,但即使混入至少 30% 对话数据,也无法维持原始 IF-eval 性能。

在任意混合比例下,我们都观察到 IF-eval 在微调中下降。
即使使用 LoRA 限制参数更新以减少遗忘,也不足以保留 IF-eval,且 LoRA 学到的知识更少。


在线策略蒸馏可恢复训练后行为
接下来,我们在内部文档微调后,尝试恢复指令遵循行为。
该行为最初由昂贵且脆弱的强化学习训练而来。
我们改用在线策略蒸馏,以旧版 Qwen3-8B 为教师,在 Tulu3 提示上训练。
这一阶段与内部文档数据无关,仅用于恢复指令遵循能力。
用旧版模型作为教师“找回”微调中丢失的能力,让在线策略蒸馏在持续学习中非常有前景。
我们可以交替进行:
- 在新数据上微调
- 用蒸馏恢复行为
让模型持续学习新知识并保持能力。
在 7:3 混合内部文档与对话数据微调后,在线策略蒸馏几乎完全恢复 IF-eval 性能,且不损失任何知识;我们还观察到对话能力与内部知识评测之间存在一定正向迁移。
| 模型 | 内部知识评测 | 指令遵循(IF-eval) |
|---|---|---|
| Qwen3-8B | 18% | 85% |
| + 中期训练(100% 文档) | 43% | 45% |
| + 中期训练(70% 文档) | 36% | 79% |
| + 中期训练 + 蒸馏 | 41% | 83% |
本质上,我们把语言模型本身当作奖励模型:高概率行为被奖励。
这与逆强化学习相关:高概率行为对应假设偏好模型中的高奖励。
任何指令微调过的开源权重模型都可以这样用作奖励模型,只需要 compute_logprobs 函数。
讨论
稠密监督大幅提升计算效率
强化学习与在线策略蒸馏都通过反向 KL 学习,修剪基础策略中的动作空间。区别在于奖励密度。
从信息论视角看:
- 强化学习每个轮次只学习 O(1) 比特信息
- 蒸馏每个轮次学习 O(N) 比特信息(N 为 Token 数)
我们做了直接对比实验:
- 从 Qwen3-8B-Base 开始
- 在 DeepMath 上运行 RL
- 从 RL 训练的模型向基础模型做在线蒸馏

结果:
蒸馏达到教师性能的速度比 RL 快 7–10 倍,计算效率提升 50–100 倍。
反向 KL 在不到 10 步就降到接近 0,而 RL 需要 70 步。
计算大幅减少的原因:
- RL 需要在评估上下文长度训练,蒸馏可在更短上下文有效学习
- 当 SFT 初始化较强时,在线蒸馏可用小得多的批次,因为每轮次信息更多,梯度噪声更小
这表明:过程监督与稠密奖励有潜力将学习效率提升一个数量级。
蒸馏可高效复用训练数据以提升数据效率
对实践者来说,收集大规模提示数据集困难且耗时,因此希望能多次复用提示。
在 RL 中,同一提示多轮训练往往导致对最终答案的简单记忆,尤其对大模型。
相反,在线策略蒸馏通过最小化反向 KL 去拟合教师完整分布,而不是记忆单一答案,允许多次采样同一提示。
我们只用数据集中随机一条提示训练 Qwen3-8B-Base,连续 20 步,每步 256 条轨迹,共 5120 条打分序列。
通常这会导致过拟合,但我们仅用单条提示就基本达到教师模型性能。

强化学习在语义策略空间中搜索
在线策略蒸馏能用少得多的训练步数复现 RL 的学习效果。
一种解释是:与预训练不同,RL 的计算开销主要不在梯度更新本身,而在搜索——滚动策略并分配信用。
预训练在高维参数空间中探索,需要海量信息且极难蒸馏。
相比之下,RL 是在语义策略空间中探索:每一步都对过去找到的策略做小幅修改,不是在参数空间探索,而是靠运气“ stumble” 到新策略。
一旦找到好策略,蒸馏就是学习它的捷径:
在线策略蒸馏不需要建模 RL 课程中的中间策略,只需要最终学到的策略。
如果我们只关心最终策略(生产场景常见),就不需要花费计算建模所有中间策略。
打个比方:科学研究要花大量资源寻找答案,一旦发现,用自然语言教给别人就简单得多。
在线策略学习作为持续学习的工具
在个性化蒸馏部分,我们展示了在线策略蒸馏能将专属训练行为重新引入模型。
这可以推广到更广泛的持续学习任务:获取新知识且不退化原有能力。
已有工作发现在线策略学习(RL)比离线策略学习遗忘更少,但 RL 只能塑造行为,不能很好地教授新知识,因此不足以支撑持续学习。
我们发现 SFT(包括离线蒸馏)在持续学习中失败,因为它会破坏行为。
我们直接用例子证明:
即使在模型自己采样的数据集上做 SFT,只要学习率大于 0,就会导致指令遵循评测性能下降!

原因可能是:
虽然期望 KL 散度为 0,但每个有限批次在实际中分布略有不同。
在这些有限批次上训练会带来非零梯度更新,使模型策略逐渐偏离原始状态。
这让“用自己样本训练”逐渐变成离线训练,导致长序列误差累积与偏离。
而在线策略蒸馏始终保持在线策略,且教师固定,学生收敛到教师的理想行为,不会像 SFT 那样退化。
这使在线策略蒸馏成为持续学习的极有前景的工具。
结论
我们探索了在线策略蒸馏在以下场景的应用:
- 训练小模型进行数学推理
- 训练可持续学习的助手
并与两种后期训练方法对比:离线蒸馏、在线策略 RL。
我们发现:在线策略蒸馏兼得二者之长
- 在线策略训练的可靠性能
- 稠密奖励信号的成本效率
后期训练是达到前沿模型能力的关键环节。
通过结合学生的在线采样与教师的稠密监督,在线策略蒸馏能以远低于高计算量 RL 的成本达到前沿性能。
我们的实现可在 Tinker cookbook 中获取。
本文用简单直接的在线策略蒸馏实例清晰展示其优势,希望未来继续研究:
- 蒸馏的新应用
- 改进教师监督的新方法
- 提升数据效率与持续学习的方式
在 Thinking Machines,我们的使命是用兼具前沿性能、适应性与个性化的 AI 模型赋能用户。在线策略蒸馏是实现这一目标的有力工具。
引用
请按以下格式引用本文:
Lu, Kevin and Thinking Machines Lab, "On-Policy Distillation",
Thinking Machines Lab: Connectionism, Oct 2025.
BibTeX:
@article{lu2025onpolicydistillation,
author = {Kevin Lu and Thinking Machines Lab},
title = {On-Policy Distillation},
journal = {Thinking Machines Lab: Connectionism},
year = {2025},
note = {https://thinkingmachines.ai/blog/on-policy-distillation},
doi = {10.64434/tml.20251026},
}