1. Software-Defined Networking (SDN) 软件定义网络
传统网络的问题
传统网络设备(交换机、路由器)把两件事混在一起:
- 控制平面:决定数据包该往哪走(路由决策)
- 数据平面:实际转发数据包
每台设备各自为政,想改网络行为就要一台一台登录进去配置,非常难管理。
SDN 的核心思想
把控制平面从设备里剥离出来,集中到一个叫 SDN Controller 的软件里统一管理:
┌─────────────────────────────┐
│ SDN Controller │ ← 大脑,决定所有转发规则
│ (OpenDaylight / ONOS) │
└──────────┬──────────────────┘
│ OpenFlow 协议下发规则
┌──────┴──────┐
▼ ▼
┌────────┐ ┌────────┐
│ 交换机 │ │ 交换机 │ ← 只负责按规则转发,不思考
└────────┘ └────────┘
三层架构
应用层 — 你写的网络应用,告诉控制器你想要什么策略(比如:这类流量优先)
控制层 — SDN Controller,把策略翻译成具体转发规则下发给设备
基础设施层 — 实际的网络设备,只管按规则转发
OpenFlow
SDN 控制器和设备之间通信用的协议,控制器通过它告诉交换机:
如果:源IP=192.168.1.1,目标端口=80
那么:从端口3转发出去
这叫一条流表规则(Flow Entry)。
为什么重要
- 数据中心可以用软件动态调整网络拓扑
- 不需要买专用硬件,普通服务器跑软件就能当交换机
- 这是 Kubernetes 网络、云计算网络的基础思想
2.Real-Time Communications (RTC)
┌─────────────────────────────────┐
│ 应用层 │
│ WebRTC / SIP / XMPP │
├─────────────────────────────────┤
│ 会话层 │
│ SDP(描述媒体格式) │
│ ICE(穿透 NAT) │
├─────────────────────────────────┤
│ 传输层 │
│ SRTP(加密音视频) │
│ DTLS(密钥协商) │
│ SCTP(数据通道) │
├─────────────────────────────────┤
│ 网络层 │
│ UDP(主要)/ TCP(备用) │
└─────────────────────────────────┘
RTP / SRTP
RTP = Real-time Transport Protocol,在 UDP 上跑,专门为音视频设计:
每个 RTP 包头包含:
┌──────────────────────────────────────┐
│ 序列号(检测丢包和乱序) │
│ 时间戳(同步音视频) │
│ SSRC(标识哪个媒体流) │
│ 负载类型(编码格式:H.264/VP8/Opus) │
└──────────────────────────────────────┘
SRTP 是加密版本的 RTP,对内容加密,防止被窃听。
RTCP
RTP 的控制协议,负责反馈网络质量:
- 丢包率是多少
- 延迟是多少
- 抖动(jitter)是多少
发送端收到这些反馈后,会动态调整码率,这叫 自适应码率(ABR)。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
├─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┤
│V=2│P│ RC │ PT │ length │
├─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┤
RTCP 深度讲解
RTCP 在整个 RTP 栈里的位置
应用层
│
├── RTP (偶数端口,如 5004) ── 实际媒体数据
└── RTCP (奇数端口,如 5005) ── 控制和统计
│
UDP
RTP 和 RTCP 永远成对出现,端口号约定是 RTP 用偶数,RTCP 用 RTP+1。
RTCP 包的基本结构
所有 RTCP 包共享同一个头部格式:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
├─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┼─┤
│V=2│P│ RC │ PT │ length │
├─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┤
字段含义:
V— 版本号,固定是 2P— 是否有填充字节RC— Report Count,包含几个报告块PT— Packet Type,包类型(200=SR, 201=RR, 202=SDES, 203=BYE, 204=APP)length— 包长度(单位是32bit字,减1)
RTCP 包类型
SR(Sender Report,200)
发送方发的,既报告自己发了什么,也包含接收质量统计:
┌─────────────────────────────────────────┐
│ Common Header │ 4 bytes
├─────────────────────────────────────────┤
│ SSRC │ 4 bytes 发送方标识
├─────────────────────────────────────────┤
│ NTP Timestamp (高32位) │ 4 bytes \
├─────────────────────────────────────────┤ ├ 绝对时间,用于音视频同步
│ NTP Timestamp (低32位) │ 4 bytes /
├─────────────────────────────────────────┤
│ RTP Timestamp │ 4 bytes 对应的RTP时间戳
├─────────────────────────────────────────┤
│ Sender's Packet Count │ 4 bytes 总共发了多少包
├─────────────────────────────────────────┤
│ Sender's Octet Count │ 4 bytes 总共发了多少字节
├─────────────────────────────────────────┤
│ Report Block(s)... │ 每个接收源一个块
└─────────────────────────────────────────┘
RR(Receiver Report,201)
纯接收方发的,不包含发送者信息,只包含接收质量统计。
Report Block(核心)
SR 和 RR 都包含这个结构,每个正在接收的 RTP 源对应一个:
┌─────────────────────────────────────────┐
│ SSRC of source │ 4 bytes 被统计的那个发送方
├─────────────────────────────────────────┤
│ fraction │ │
│ lost │ cumulative lost │ 4 bytes
├─────────────────────────────────────────┤
│ extended highest seq num │ 4 bytes
├─────────────────────────────────────────┤
│ interarrival jitter │ 4 bytes
├─────────────────────────────────────────┤
│ last SR │ 4 bytes
├─────────────────────────────────────────┤
│ delay since last SR │ 4 bytes
└─────────────────────────────────────────┘
各字段计算方式(代码级别)
丢包率 fraction lost
// 上次报告以来的丢包比例,0-255 对应 0%-100%
// expected = 这段时间内期望收到的包数
// received = 实际收到的包数
uint32_t expected = extended_max_seq - last_extended_max_seq;
uint32_t received = packet_count - last_packet_count;
uint32_t lost = expected - received;
uint8_t fraction_lost;
if (expected == 0 || lost <= 0)
fraction_lost = 0;
else
fraction_lost = (lost << 8) / expected; // 左移8位相当于乘256
累计丢包数 cumulative lost
// 从开始到现在总共丢了多少包,24bit有符号整数
int32_t cumulative_lost = total_expected - total_received;
// 范围 -2^23 到 2^23-1,负数表示有重复包
序列号 extended highest sequence number
// RTP序列号是16bit,会回绕(65535→0)
// 这里扩展成32bit,高16位是回绕次数,低16位是当前序列号
uint32_t extended_seq = (cycles << 16) | max_seq;
Jitter 抖动计算
这是最精妙的部分,用指数加权移动平均:
// RFC 3550 定义的 jitter 计算
// D(i,j) = 包j和包i之间的到达时间差 - 发送时间差
double compute_jitter(
uint32_t recv_time_i, // 包i的接收时间(RTP时间戳单位)
uint32_t recv_time_j, // 包j的接收时间
uint32_t send_time_i, // 包i的RTP时间戳
uint32_t send_time_j, // 包j的RTP时间戳
double jitter_prev // 上一次的jitter值
) {
// 到达间隔差
int32_t d = (recv_time_j - recv_time_i)
- (send_time_j - send_time_i);
if (d < 0) d = -d; // 取绝对值
// RFC 3550 公式:J(i) = J(i-1) + (|D(i-1,i)| - J(i-1)) / 16
return jitter_prev + ((double)d - jitter_prev) / 16.0;
}
除以16而不是取平均,是因为这样对突发抖动响应快,对平稳期遗忘慢,是个低通滤波器。
If Si is the RTP timestamp from packet i, and Ri is the time of
arrival in RTP timestamp units for packet i, then for two packets
i and j, D may be expressed as
D(i,j) = (Rj - Ri) - (Sj - Si) = (Rj - Sj) - (Ri - Si)
The interarrival jitter SHOULD be calculated continuously as each
data packet i is received from source SSRC_n, using this
difference D for that packet and the previous packet i-1 in order
of arrival (not necessarily in sequence), according to the formula
J(i) = J(i-1) + (|D(i-1,i)| - J(i-1))/16
Whenever a reception report is issued, the current value of J is
sampled.
RTT 往返延迟计算
RTCP 巧妙地用时间戳计算 RTT,不需要额外的 ping:
// 发送方 A 在 SR 里写入当前 NTP 时间(LSR字段)
// 接收方 B 收到 SR 后,在 RR 里写:
// last_sr = SR里的NTP时间戳中间32位
// delay_since_last_sr = 从收到SR到发出RR经过了多少时间
// 发送方 A 收到 RR 后计算RTT:
uint32_t rtt = now - last_sr - delay_since_last_sr;
// now = 当前时间
// last_sr = RR里带回来的,我发SR时的时间
// delay_since_last_sr = B处理花了多少时间(排除掉)
// 剩下的就是纯网络往返时间
// 单位是 1/65536 秒,转换成毫秒:
double rtt_ms = (double)rtt / 65536.0 * 1000.0;
自适应码率(ABR)怎么用这些数据
发送方收到 RTCP RR 之后,根据统计信息调整发送策略:
void adjust_bitrate(RTCPReport* report) {
double fraction_lost = report->fraction_lost / 256.0;
double jitter_ms = report->jitter / 90.0; // 90kHz时钟
double rtt_ms = compute_rtt(report);
if (fraction_lost > 0.10) {
// 丢包超过10%,降低码率
current_bitrate *= 0.85;
}
else if (fraction_lost < 0.02 && jitter_ms < 20.0) {
// 丢包很少且抖动小,试探性提高码率
current_bitrate *= 1.05;
}
if (rtt_ms > 200.0) {
// 延迟太高,降低码率减少缓冲区积压
current_bitrate *= 0.90;
}
// 限制在合理范围内
current_bitrate = clamp(current_bitrate, MIN_BITRATE, MAX_BITRATE);
encoder_set_bitrate(current_bitrate);
}
真实的 WebRTC 用的是更复杂的 GCC 算法(Google Congestion Control),还会分析包的到达时间斜率来预测拥塞,但基本思路和这个一样。
RTCP 发送间隔
RTCP 不能发太频繁,RFC 3550 规定 RTCP 流量不超过总带宽的 5%:
// 简化版间隔计算
double rtcp_interval(int senders, int members, double avg_rtcp_size, double bandwidth) {
double rtcp_bw = bandwidth * 0.05; // 5% 给 RTCP
double interval = avg_rtcp_size * members / rtcp_bw;
// 最小间隔 5 秒,防止网络刚启动时轰炸
if (interval < 5.0) interval = 5.0;
// 加随机抖动,防止所有人同时发
return interval * (0.5 + (rand() / RAND_MAX));
}
WebRTC 发送方码率预估实现解析
WebRTC使用的是Google Congestion Control (简称GCC)拥塞控制,目前有两种实现:
* 旧的实现是接收方根据收到的音视频RTP报文, 预估码率,并使用REMB RTCP报文反馈回发送方。 * 新的实现是在发送方根据接收方反馈的TransportFeedback RTCP报文,预估码率。基于延迟的拥塞控制原理
先来看下Google Congestion Control(GCC)的标准草案:https://tools.ietf.org/html/draft-ietf-rmcat-gcc-02
结合草案,可以得知GCC是基于网络延迟梯度的拥塞控制算法,判断的依据如下图:
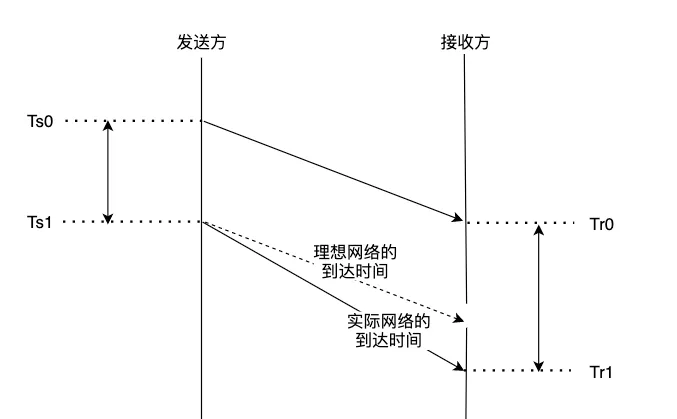
发送方发送两个包组的间隔为 : Ds = Ts1 - Ts0
接收方接收两个包组的间隔为: Dr = Tr1 - Tr0
如果网络没有任何抖动,那么 [ delta = Dr - Ds ] 应该是一个恒定不变的值,但是现实中网络有抖动、拥塞、丢包等情况,所以delta也是一个抖动的值。
GCC通过测量delta,来判断当前网络的使用情况,分为 OverUse (过载),Normal(正常),UnderUse(轻载) 这三种情况。
有同学可能会问,发送方和接收方时钟不统一,怎么计算差值呢,需要做时间对齐或者NTP同步吗?
不需要,因为我们对比的是delta,只需要单位一致即可,举个例子:
seq1的包 发送时间为 16000ms(发送方时钟),接收时间为 900ms(接收方时钟)
seq2的包 发送时间为 16001ms(发送方时钟),接收时间为 905ms(接收方时钟)
那么延迟梯度delta=(905-900) - (16001-16000) = 4
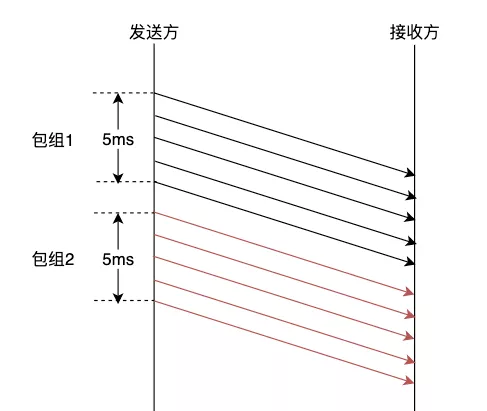
Pacing和包组
值得注意的是,延迟梯度的判断是以包组为单位的,而且必须在发送方开启pacing发送, 有以下几点原因:
单个包测量误差会过大,基于包组的测量更能反应网络的情况。
burst发送容易冲击网络,影响测量的精度。
那么怎么判断哪几个包属于一个包组呢,非常简单,按发送方的pacing速率分包组。
WebRTC pacing默认是5ms一个包组,如下图所示
TransportFeedback RTCP报文
再来看看transport-feedback的包结构:https://tools.ietf.org/html/draft-holmer-rmcat-transport-wide-cc-extensions-01

解析这个报文,我们可以得到下面的信息:
- 接收到的包seq和包的接收时间
- 丢失的包seq
- 可以看到本质上transport-feedback是接收方对数据的ACK,并且捎带了接收的延迟梯度。
发送方码率预估
收到transport-feedback报文后需要怎么处理,结合GCC的算法来看,分为以下几步:
1.计算接收方ack了多少个字节, 统计在采样的时间窗口内接收方的接收速率
看看GCC怎么说:

按照这个算法实现acked_bitrate_estimate,可以计算出接收方在当前时间窗口内的接收速率。
2.将包按包组归类, 计算包组的发送时间 接收时间的差值
在前面的【Pacing和包组】中已经讲过,这里不再赘述
3.按包组的delta, 进行网络状态评估
GCC的标准草案里面使用的是卡尔曼滤波器(接收方评估),发送方评估默认的实现是Trendline Filter。
基本的原理是最小二乘法, 将多个时间点的网络抖动(delta)拟合成一条直线,如下图所示:
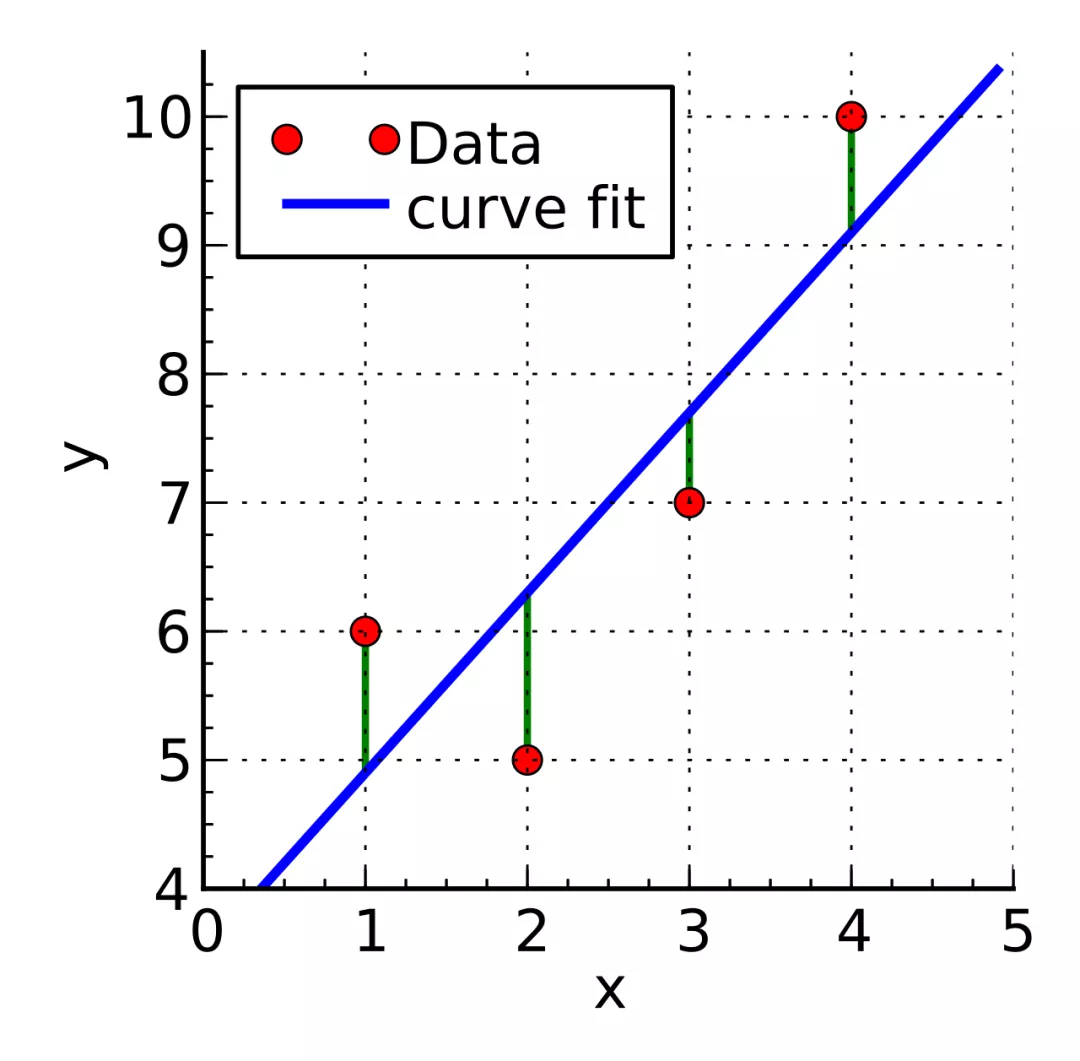
根据直线斜率的变化趋势判断网络的负载情况。
上面已经得到了包组的delta,对delta做平滑计算后,按照(时间点, 平滑后的delta), 可以在坐标系上绘制出散点图,使用最小二乘法拟合出delta随时间变化的直线,根据直线斜率计算出变化趋势。
来看看GCC里面的说法:

- m(i)为i时刻的包组delta,del_var_th(i)为当前判断是否过载的门槛
- m(i) < -del_var_th(i),判断为under-use(低载)
- m(i) > del_var_th(i) 且持续至少overuse_time_th时长,判断为over-use(过载)

del_var_th必须动态调整,不然可能会在跟TCP的竞争中被饿死(出于公平性考虑)。过大的del_var_th会对延迟变化不敏感,过小的del_var_th则会过于敏感,抖动容易被频繁误判为过载,必须动态调整,才能和基于丢包的连接(比如TCP)竞争。
根据探测的网络情况, 预估码率
总体的思想是根据当前接收方的接收码率,结合当前的网络负载情况,进行AIMD码率调整:
- 在接近收敛前,使用乘性增,接近收敛时使,用加性增。
- 当网络过载时,使用乘性减。

在Decrease状态下,会不停的计算平均最大码率(average max bitrate),当前预估码率和平均最大码率差值在3个标准差以内时,进行乘性增,否则进行加性增。如果包到达速率超过了平均最大码率的3个标准差,那么需要重新计算平均最大码率。

乘性增期间,每秒最多增加8%的码率

加性增期间,每个rtt增加“半个”包大小

评估出的码率不能超过接收速率的1.5倍

当探测到网络过载时,按照0.85的速率降低码率
发送方码率预估的算法流程
将上面的几步结合起来,可以得到一个大致的算法框架
struct FeedbackResultVector {
int64_t send_time_ms; // 包发送时间(发送时记录)
int64_t recv_time_ms; // 包接收时间(从TransportFeedback RTCP报文解析得到)
int packet_size; // 包大小
};
// 解析TransportFeedback RTCP报文
FeedbackResultVector feedback_result_vec =
TransportFeedbackRtcp.Parse(rtcp_feedback);
// 遍历每个包, 进行处理
for (feedback_result : feedback_result_vec) {
double delta = 0.0;
// 计算ack速率(接收方接收速率)
AckBitrateEstimate.Update(now_ms, feedback_result.packet_size);
// 把接收反馈包按照包组分类,计算包组delta
bool compute_delta = PacketGroup.AddPacket(feedback_result, delta);
if (comupute_delta) {
// 探测网络状态
TrendLineFilter.Detect(delta);
// 根据GCC状态机,进行AIMD码率调整
AimdRateControl.Update(
TrendLineFilter.NetState(),
AckBitrateEstimate.Bitrate()
);
}
}
Reference:
WebRTC研究:包组时间差计算-InterArrival: https://blog.jianchihu.net/webrtc-research-interarrival.html
WebRTC研究:Trendline滤波器-TrendlineEstimator: https://blog.jianchihu.net/webrtc-research-trendlineestimator.html
袁荣喜的一个GCC C语言的实现: https://github.com/yuanrongxi/razor
3.SNMP
当前可探索的层级结构:
- 架构模型 → 深入可到:NMS 管理站 / SNMP Agent(含 AgentX 协议)/ MIB 数据库
- MIB 管理信息库 → 深入可到:OID 树形结构 / MIB-II 的 10 个功能组(含接口表、IP 表、ARP 表)
- PDU 消息类型 → 完整展开 6 种操作报文(Get / GetNext / GetBulk / Set / Trap / Inform)
- 版本演进 → v1 明文陷阱 → v2c Counter64 → v3 USM 安全模型(HMAC 认证 + AES 加密全流程)
- 安全模型 USM → 密钥本地化算法 / 防重放时间窗口 / AES-CFB 加密过程(含伪代码)
- 常用工具 → snmpwalk 命令示例 / Zabbix LLD 自动发现 / Prometheus SNMP Exporter 完整配置
4.Cilium
Cilium —— eBPF 驱动的现代网络安全平台
Cilium provides networking and security capabilities for containerized apps, microservices, and virtual machines.
0. 根节点:Cilium 到底是什么?
最顶层可以这样理解:
Cilium 是一个面向云原生环境的网络、安全与可观测性平台。
再展开一点:
Cilium 主要用于 Kubernetes、容器、微服务以及相关云原生基础设施中,负责让服务之间能够通信、控制谁能访问谁、并帮助你看清楚网络里发生了什么。 Cilium 官方也将其定位为面向 Kubernetes 等云原生环境的 networking、security、observability 项目。(Cilium)
所以,Cilium 不是单纯的“网卡插件”,也不是单纯的“防火墙”,而是把下面几类能力组合在了一起:
Cilium
├── 网络连接 Networking
├── 网络安全 Security
├── 可观测性 Observability
├── 负载均衡 Load Balancing
├── 服务网格 Service Mesh
├── 多集群连接 Cluster Mesh
└── eBPF 数据平面 eBPF Datapath
1. 第一层递归:Cilium 解决什么问题?
在现代系统里,应用通常不是一个大程序,而是很多小服务组成的。
比如一个电商系统:
用户请求
↓
frontend 前端服务
↓
user-service 用户服务
↓
order-service 订单服务
↓
payment-service 支付服务
↓
database 数据库
这些服务可能运行在:
容器 Container
Pod
Kubernetes Node
不同 Kubernetes 集群
虚拟机 VM
云服务器
本地数据中心
这就带来三个核心问题:
问题 1:它们怎么连?
问题 2:谁允许访问谁?
问题 3:出了问题怎么看见?
Cilium 对应给出三个核心答案:
怎么连? → Networking
谁能访问谁? → Security / Network Policy
怎么观察? → Observability / Hubble
2. 第二层递归:Networking 是什么?
2.1 Networking 的最简单解释
Networking 就是让服务之间能互相通信。
比如:
frontend 可以访问 backend
backend 可以访问 database
payment 可以访问 external-bank-api
在 Kubernetes 中,服务通信不是简单的“机器 A 连机器 B”。因为 Pod 会频繁创建、销毁、迁移:
今天 backend 的 IP 是 10.0.1.23
明天 backend 重启后变成 10.0.2.88
后天 backend 扩容成 10 个 Pod
如果安全规则、路由规则都依赖固定 IP,就会非常脆弱。
所以 Cilium 要解决的是:
动态工作负载之间的稳定通信问题
也就是:
应用在变
Pod 在变
IP 在变
节点在变
但通信规则和安全语义要稳定
2.2 继续递归:Cilium 怎么实现 Networking?
Cilium 的核心做法是:
用 eBPF 在 Linux 内核中处理网络数据包
也就是说,当一个 Pod 发出网络请求时,请求不只是走传统的 iptables 规则,而是可以被 Cilium 加载到内核中的 eBPF 程序处理。
Cilium 文档中提到,它用 eBPF 实现分布式负载均衡,并使用高效的哈希表来支持高服务密度和大规模低延迟场景;它也可以在 socket 层重写服务连接,从而避免逐包 NAT 的开销,并可替代 kube-proxy。(docs.cilium.io)
递归拆开:
Cilium Networking
├── Pod-to-Pod 通信
├── Service 负载均衡
├── 集群内东西向流量
├── 集群外南北向流量
├── 多集群互联
├── 外部服务访问
└── kube-proxy 替代
2.3 东西向流量和南北向流量
这两个词很常见。
东西向流量 East-West Traffic
指系统内部服务之间的通信。
例如:
frontend → user-service
user-service → order-service
order-service → payment-service
它们都在集群内部,像地图上左右移动,所以叫“东西向”。
南北向流量 North-South Traffic
指外部用户或外部系统和集群之间的通信。
例如:
用户浏览器 → Kubernetes Ingress / Gateway → frontend
payment-service → 银行 API
也就是“外部进来”或“内部出去”。
Cilium 同时处理这两类流量。
3. 第二层递归:Security 是什么?
3.1 Security 的最简单解释
Security 就是控制谁能访问谁。
不是所有服务都应该互相访问。
比如:
frontend 可以访问 user-service
frontend 不应该直接访问 database
order-service 可以访问 payment-service
random-test-pod 不应该访问 payment-service
这就是网络安全策略。
3.2 继续递归:传统网络安全有什么问题?
传统网络安全通常基于:
源 IP
目标 IP
端口
协议
例如:
允许 10.0.1.23 访问 10.0.2.10:5432
问题是,在 Kubernetes 中 IP 经常变化:
Pod 重启 → IP 变
Pod 迁移 → IP 变
Pod 扩容 → IP 数量变
节点故障 → 调度位置变
所以基于 IP 的安全策略在动态环境中很容易变得脆弱。
3.3 Cilium 的核心安全思想:身份,而不是 IP
Cilium 的重要思想是:
不要只相信 IP
要识别工作负载身份
也就是说,它更关心:
这个请求来自哪个服务?
这个服务有哪些 Kubernetes labels?
它属于哪个 namespace?
它是不是 payment 组件?
它是不是 production 环境?
而不是只看:
它现在的 IP 是多少?
Cilium 官方文档说明,Cilium Network Policy 提供 L3-L7 的 identity-aware enforcement;为避免依赖易变的 IP 地址,Cilium 会给共享相同安全策略的应用容器分配 security identity,并把身份关联到应用发出的网络包上。(docs.cilium.io)
这就是:
Identity-based Security
也就是基于身份的安全。
4. 第三层递归:L3、L4、L7 是什么?
Cilium 经常说自己支持:
L3-L7 network policy
这是什么意思?
它来自网络模型。
4.1 L3:网络层
L3 主要关心 IP。
例如:
允许访问 10.0.0.0/16
禁止访问 192.168.1.0/24
L3 规则回答的是:
能不能访问这个网络地址?
4.2 L4:传输层
L4 主要关心端口和协议。
例如:
允许访问 TCP 443
允许访问 TCP 5432
禁止访问 TCP 6379
L4 规则回答的是:
能不能访问这个端口?
比如:
frontend → backend:8080 允许
frontend → database:5432 禁止
4.3 L7:应用层
L7 关心具体应用协议,比如:
HTTP
gRPC
Kafka
DNS
L7 规则可以细到:
只允许 GET /public/*
禁止 POST /admin/*
只允许访问 api.example.com
只允许调用某个 gRPC 方法
Cilium 文档中给出的例子包括按 HTTP method、URL path、gRPC call 等进行过滤,例如只允许 GET 请求访问 /public/.*。(docs.cilium.io)
所以 Cilium 的安全能力可以从粗到细递归展开:
Cilium Security
├── L3:控制 IP / CIDR
├── L4:控制端口 / 协议
├── DNS:控制域名访问
└── L7:控制 HTTP / gRPC / Kafka 等应用请求
5. 第二层递归:Observability 是什么?
5.1 Observability 的最简单解释
Observability 就是看清楚系统里发生了什么。
在微服务系统中,问题经常是这样的:
用户说支付失败
开发说代码没问题
运维说服务都活着
安全说策略没改过
网络说流量好像被拒绝了
这时你需要回答:
哪个服务访问了哪个服务?
请求有没有被允许?
被哪条策略拒绝了?
DNS 解析到了哪里?
HTTP 请求路径是什么?
延迟在哪里变高了?
这就是可观测性。
5.2 Cilium 的可观测性组件:Hubble
Cilium 生态中用于网络可观测性的核心组件叫 Hubble。
Hubble 可以帮助你看到:
服务之间的流量
请求方向
源身份
目标身份
DNS 请求
HTTP / gRPC 信息
策略允许或拒绝
服务依赖关系图
Cilium 文档描述 Hubble 是一个集成的可观测性平台,提供实时 service map、带 identity 和 label metadata 的流量可见性、DNS-aware filtering 和协议级洞察;Cilium 也能与 Prometheus、Grafana 等监控系统集成。(docs.cilium.io)
递归展开:
Observability
├── Flow Visibility:看到网络流
├── Service Map:看到服务依赖图
├── DNS Visibility:看到域名访问
├── Policy Verdict:看到允许 / 拒绝
├── Metrics:指标
├── Tracing:追踪
└── Troubleshooting:排障
6. 第二层递归:eBPF 是什么?
6.1 eBPF 的最简单解释
eBPF 是一种可以在 Linux 内核中安全运行小程序的技术。
更直白一点:
以前想改变内核行为:
要么改 Linux 内核源码
要么写内核模块
现在:
可以用 eBPF 在内核中挂载安全、受限制的小程序
eBPF 官方文档将其描述为起源于 Linux 内核的技术,可以在操作系统内核这样的特权上下文中运行沙箱程序,并且可以安全、高效地扩展内核能力,而不需要修改内核源码或加载内核模块。(ebpf.io)
6.2 继续递归:为什么网络、安全、观测都喜欢 eBPF?
因为网络包本来就要经过 Linux 内核。
如果你能在内核路径上做判断,就可以更早、更快地处理问题:
网络包刚进入节点
↓
eBPF 程序检查
↓
决定允许、拒绝、转发、负载均衡、记录事件
而不是等包走完很多传统路径之后再处理。
所以 eBPF 很适合:
网络转发
负载均衡
网络策略
安全审计
系统调用观测
性能分析
流量追踪
eBPF 程序是事件驱动的,可以挂在系统调用、函数入口/出口、内核 tracepoint、网络事件等 hook 点上;加载进内核前还会经过 verifier 检查,以确保程序不会伤害系统、不会无限循环、不会越界访问内存。(ebpf.io)
7. 第三层递归:Cilium 和 eBPF 的关系
可以这样理解:
eBPF 是底层技术
Cilium 是基于 eBPF 构建出来的网络安全平台
类比:
eBPF 像发动机技术
Cilium 像一辆完整的车
eBPF 提供能力
Cilium 把能力产品化、平台化、Kubernetes 化
再换个比喻:
Linux 内核 = 城市道路系统
eBPF = 可以安装在路口的智能交通规则
Cilium = 交通管理平台
Kubernetes Pod = 城市里的车辆
Network Policy = 交通规则
Hubble = 监控摄像头和交通大屏
当一个 Pod 发出请求时:
Pod 发包
↓
Linux 内核网络路径
↓
Cilium eBPF 程序拦截 / 判断 / 转发
↓
检查身份
↓
检查策略
↓
做负载均衡
↓
记录可观测数据
↓
请求到达目标服务
8. 第四层递归:Cilium 的控制平面和数据平面
理解 Cilium,最好区分两个概念:
控制平面 Control Plane
数据平面 Data Plane
8.1 数据平面:真正处理流量的地方
数据平面负责处理真实网络包。
在 Cilium 中,数据平面主要由:
eBPF programs
eBPF maps
Linux kernel hooks
组成。
它做这些事情:
转发数据包
执行网络策略
做服务负载均衡
记录流量信息
处理 NAT / 路由相关逻辑
8.2 控制平面:生成规则和配置的地方
控制平面负责理解 Kubernetes 状态。
例如:
有哪些 Pod?
Pod 的 labels 是什么?
有哪些 Service?
Service 后面有哪些 Endpoint?
有哪些 NetworkPolicy?
哪些身份对应哪些 workloads?
Cilium 的 cilium-agent 运行在每个节点上,接受来自 Kubernetes 或 API 的配置,理解网络、负载均衡、网络策略、可见性与监控需求;它还监听 Kubernetes 等编排系统的事件,并管理 Linux 内核用于控制容器网络访问的 eBPF 程序。(docs.cilium.io)
递归展开:
Cilium Agent
├── 监听 Kubernetes API
├── 发现 Pod / Service / Endpoint / Policy
├── 计算身份 Identity
├── 生成或更新 eBPF 配置
├── 管理 eBPF maps
└── 让内核按最新规则处理流量
9. 用一个完整请求递归串起来
假设有这样一个请求:
frontend Pod 想访问 payment-service
Cilium 会如何参与?
9.1 第一步:frontend 发起请求
frontend → payment-service
应用代码可能只是访问:
http://payment-service/pay
它不关心 payment-service 背后有多少个 Pod,也不关心它们在哪个节点。
9.2 第二步:Cilium 处理服务负载均衡
Kubernetes Service 背后可能有多个 payment Pod:
payment-service
├── payment-pod-1
├── payment-pod-2
└── payment-pod-3
Cilium 可以用 eBPF 做服务负载均衡,把请求转发到某个后端 Pod。
9.3 第三步:Cilium 检查身份
Cilium 不只是看源 IP,而是识别:
源服务是谁?
它有哪些 labels?
它在哪个 namespace?
它的 security identity 是什么?
例如:
app: frontend
namespace: production
目标可能是:
app: payment
namespace: production
9.4 第四步:Cilium 检查策略
假设策略是:
允许 app=frontend 访问 app=payment 的 TCP 443
禁止其他服务访问 payment
那么:
frontend → payment:443 允许
debug-pod → payment:443 拒绝
frontend → payment:22 拒绝
如果启用了 L7 策略,还可以继续检查:
GET /pay/status 允许
POST /admin/refund 拒绝
9.5 第五步:Cilium 记录可观测数据
Hubble 可以记录:
源:frontend
目标:payment
端口:443
协议:HTTP
路径:/pay
结果:FORWARDED / DROPPED
原因:policy allowed / policy denied
于是排障时你能看到:
是谁访问了谁
什么时候访问
访问是否成功
如果失败,为什么失败
10. Cilium 为什么适合微服务?
微服务的特点是:
服务多
实例多
变化快
调用关系复杂
边界模糊
传统网络安全更适合静态环境:
固定机器
固定 IP
固定端口
固定边界
而 Kubernetes / 微服务是动态环境:
Pod 随时重建
IP 随时变化
服务随时扩缩容
调用链随时变复杂
所以 Cilium 的优势是:
用身份代替 IP
用策略描述意图
用 eBPF 提升性能
用 Hubble 增强可见性
用 Kubernetes labels 对齐应用语义
也就是说,它不是只在“网络层”理解系统,而是试图在网络层、身份层、应用层之间建立连接。
11. 用一句递归定义总结 Cilium
可以这样定义:
Cilium
= 一个云原生网络安全平台
= 用 eBPF 在 Linux 内核中高效处理网络流量
= 为容器、微服务和虚拟机等工作负载提供连接、安全和可观测能力
= 通过身份而不是脆弱的 IP 来执行访问控制
= 通过 Hubble 让服务间通信变得可见
再压缩成一句话:
Cilium 是一个基于 eBPF 的云原生网络、安全与可观测性平台,它把 Linux 内核变成一个可编程的数据平面,用来高效连接、保护和观察容器化应用、微服务以及相关工作负载。